Figure 1: Classes of Computer Misuse Techniques
Practical Architectures for
Survivable Systems and Networks
(Phase-Two Final Report)
30 June 2000
©Copyright 2000 SRI International,
and freely available for noncommercial reuse
Peter G. Neumann
Computer Science Laboratory
SRI International, Room EL-243
333 Ravenswood Avenue
Menlo Park CA 94025-3493
Telephone: 1-650-859-2375
Fax: 1-650-859-2844
E-mail: Neumann@CSL.sri.com
http://www.csl.sri.com/neumann
Acknowledgment of Support and Disclaimer: This report is based upon work
supported by the U.S. Army Research Laboratory (ARL), under Contract
DAKF11-97-C-0020. Any opinions, findings, conclusions, or recommendations
expressed herein are those of the author and do not necessarily reflect the
views of the U.S. Army Research Laboratory. The Government contact is
Anthony Barnes (BarnesA@arl.mil), 1-732-427-5099.
[NOTE: This report represents a somewhat personal view of some potentially effective approaches toward developing, configuring, and operating highly survivable system and network environments. It is accessible on-line in three forms, the first two for printing, the third for Web browsing in nicely crosslinked html:
http://www.csl.sri.com/neumann/survivability.ps
http://www.csl.sri.com/neumann/survivability.pdf
http://www.csl.sri.com/neumann/survivability.htmlConstructive feedback is always welcome. Many thanks. PGN]
Abstract: This report summarizes the analysis of information system survivability. It considers how survivability relates to other requirements such as security, reliability, and performance. It considers a hierarchical layering of requirements, as well as interdependencies among those requirements. It identifies inadequacies in existing commercial systems and the absence of components that hinder the attainment of survivability. It recommends specific architectural structures and other approaches that can help overcome those inadequacies, including research and development directions for the future. It also stresses the importance of system operations, education, and awareness as part of a balanced approach toward attaining survivability.
The field of endeavor addressed in this report is inherently open ended. New research results and new software components are appearing at a rapid pace. For this reason, the report stresses fundamentals, and is intended to be a guide to certain principles and architectural directions whose systematic use can lead to systems that are meaningfully survivable. In that spirit, the report is intended to serve as a coherent resource from which many further resources can be gleaned by following the cited references and URLs.
The report is relatively modest in its intent. It does not try to solve all the problems of how to design, implement, administer, maintain, and use highly survivable systems and networks. Those problems require future research and greater discipline in system development and operations. Nevertheless, the report represents a substantive starting point.
The document can be useful to developers of systems with critical requirements. It can also be useful in connection with anyone wanting to teach or learn the basics of system and network survivability. The Army Research Laboratory and the Software Engineering Institute have sponsored workshops on Information Survivability (InfoSurv). In part as a result of Paul Walczak's efforts at ARL relating to this project, several universities (Maryland, Pennsylvania, Tennessee-Knoxville, Georgia Tech) have had courses using the contents of our interim first-phase report (January 1999). Appendix A characterizes some of the curriculum issues relating to survivability. We have intentionally not tried to spell out specific course materials lecture by lecture, but rather have tried to provide basic directions that such courses might address.
Printable versions of this document contain URLs for many relevant Web resources. The browsable html version may be preferable for Web users, because it contains hot links to those resources.
Systems and networks with critical survivability requirements are extremely difficult to specify, develop, procure, operate, and maintain. They tend to be subject to many threats, laden with risks, and difficult to use wisely. By systems, we include operating systems, dedicated application systems, systems of systems, and networks viewed as systems.
We begin with several observations.
The above observations motivate a simple statement of the goals of our project and of this report. To surmount these realities, we seek to
It is absolutely essential to realize that there are no easy answers for achieving survivable systems and networks. This report does not pretend to be a cookbook. Cookbook approaches are doomed to fail, because of the intrinsic multidimensionality of the survivability problems, the inadequacies of the existing infrastructures, the fact that the underpinnings are continually in flux, and the fact that no one solution or small set of solutions fits all applications. We cannot merely follow tried-and-true recipes, because no foolproof recipes exist. For these reasons, we emphasize here the need for in-depth understanding of the basic issues, the recognition and pervasive adherence to sensible principles, the fundamental importance of insights gleaned from past experience, and the urgency of pursuing significant R&D approaches and incorporating them into practical systems. Thus, we include many references to primary literature sources, with the hopes that diligent readers will pursue them. The successful integration of the best of these concepts is absolutely fundamental to the development, procurement, and use of systems and networks that can fulfill requirements for high survivability.
To satisfy the goals stated above, we take a strongly system-oriented approach. Survivability of systems and networks is not an intrinsic low-level property of subsystems in the small. Instead, it is an emergent property -- that is, a property that has meaning primarily in the overall context to which it relates. Emergent properties can be defined in terms of the concepts of their own layers of abstraction, but generally not completely in terms of individual components at lower layers. That is, an emergent property is a property that arises as a result of the composition of lower-layer components and that is not otherwise evident. Emergent properties may be positive (such as human safety and system survivability) or negative (such as unforeseen interactions among components -- for example, covert channels that exist only when components are combined). Simply composing a system or network out of its components provides no certainty whatever that the resulting whole will work as desired, even if the components themselves seem to behave properly. One of the most important challenges confronting us is to be able to derive the emergent properties of a system in the large from the properties of its components and from the manner in which they are integrated.
There is an important body of work devoted to dependable systems (especially in Europe) and to high-assurance systems (especially in the U.S.). These are really aspects of the same thing. A system should be capable of satisfying its requirements, dependably and with appropriate assurance, whatever those requirements are. Survivability is an overarching requirement that implies security, reliability, adequate performance, and many other subrequirements.
The following recommendations are ordered roughly according to how they appear in the development and operational cycles. Their relative importance is considered at the end of the enumeration.
It is always desirable to indicate relative priorities in which such recommendations need to be addressed, and their relative difficulty. Unfortunately, survivability, security, and reliability are weak-link phenomena that can be compromised in many different ways. Thus, all the above recommendations can have considerable payoffs in efforts to develop survivable systems, for many different reasons -- because of the holistic nature of the desired requirements and the inherent complexity of their realization.
It is difficult to pinpoint the recommendations that might provide the greatest payoffs -- precisely because of the weak-link phenomena. Besides, searching for easy answers is a common failing, especially in complex situations in which there are no easy answers. However, in general the greatest long-term benefits seem to accrue from up-front efforts, that is, relating to establishing sound requirements, system designs, and architectures, rather than focusing on software development, operations, topical preventive measures, and maintenance. That is why we have chosen the order of recommendations as above, implicitly placing emphasis on the items in that order. Nevertheless, there would be major benefits from almost all the items above.
In particular, the establishment of mission models (1) and fundamental requirements (2) might have the greatest benefits of all, because it could provide the basis for system developments and procurements of systems. However, past experience with the DoD Trusted Computer Security Evaluation Criteria and system procurements suggests that this is not an easy path, and that even if we had a superb set of requirements, they might be largely ignored.
Stronger architectures, components, protocols, and cryptographic infrastructures (3, 4, 5, 6, 7) are all potentially important to the development process. Ideally, they need to be motivated by strong requirements. In the absence of such explicit requirements in the past, systems have developed according to a slow migration path that is driven primarily by perceived market considerations, which have not converged on what is needed. Incentivizing main-stream developers (8) and promotion of source-available software and open systems (9,10) are both vital, particularly if the latter inspires greater advancement by the former.
Real-time analysis of system monitoring and rapid response (11) are essential, but primarily as a last resort in the presence of vulnerable systems. Ideally, greater emphasis on up-front requirements and architectures would diminish the need for real-time analysis -- at least with respect to outsider attacks. However, this is not likely to happen for a long time.
Building systems that are more easily administered and simplifying the role of system administration (12) would yield great savings in labor and cost, as well as minimizing emergency remediation (especially in combination with more intelligent real-time analysis). However, outsourcing of administrators is a highly riskful proposition. (Recently, system administrators in SRI's Computer Science Laboratory complained to their counterparts at Fort Huachuca relating to a host within the Fort Huachuca domain that was issuing repeated domain name service (DNS) requests to a machine within our CSL network that is not a name server. The human response was in effect, well, it is after 3 in the afternoon on Friday, and our admin efforts are outsourced to a contractor whose availability is uncertain. Sorry.)
Furthermore, long-term research and development issues must not be ignored (13). Specific directions for R&D are discussed in Section 9.2 of this report.
When attempting to confront a complex system problem, considerable benefit can result from considering the situation in the large (top-down), rather than attempting to patch together a bunch of existing would-be solutions (bottom-up). The bottom-up approach typically makes unrealistic assumptions about the independence of subproblems. The holistic approach taken here attempts to address the whole system, and then see what can be done to partition the problems while also dealing with the interactions among the components. In some cases, it is advantageous to consider a somewhat more general problem to gain insights that cannot be seen from the more specific problem (especially when the specific problem is not well understood). We believe that such an approach is advantageous in developing complex systems.
It is clear that systematic use of strong authentication (including avoidance of fixed passwords) could have an enormous impact all by itself on system integrity. Firewalls that are secure and properly administered would help. Highly survivable servers would be a considerable benefit. More precise requirements would have a major influence on system procurements - if those requirements were satisfied. Serious consideration of an open-design policy of extensive early review and the use of source-available software where appropriate may in the long run be essential to overcome the limitations of proprietary closed-source systems that cannot fulfill the desired requirements. Alternative architectures including a secure mobile-code paradigm have considerable promise, particularly in connection with thin-client systems and highly trustworthy servers. But the bottom line here is that the basic computer-communication infrastructure is fundamentally inadequate today.
The use of structure is particularly important in designing, implementing, and maintaining systems and networks. The combination of architectural principles and the use of good software engineering and system engineering practice can be extremely effective. In particular, it is vital to address the full range of survivability-relevant requirements from the outset; it is typically very difficult to make retrofits later. The notion of generalized dependence considered in this report permits us to avoid needing total dependence on the correctness of certain other components -- many of which have unknown trustworthiness, or are inherently suspect. This is the notion of obtaining trustworthiness despite the relative untrustworthiness of certain components. This concept is increasingly important in highly distributed computing environments. Preventing or seriously hindering denial-of-service attacks is a particularly important architectural issue. The mobile-code paradigm offers many potential advantages in such environments, but it also requires some dramatic improvements in the security, reliability, and robustness of certain critical components.
It is a difficult course that we must follow. It is evidently a never-ending course, for a variety of reasons. As the requirements continue to be better understood, more is demanded. As technical improvements are introduced, new vulnerabilities are typically introduced. As technology continues to offer new functional opportunities, and as systems tend to operate closer to their technological limits, the vulnerabilities, threats, and risks are increased accordingly, requiring much greater care. Operational and administrative challenges are continually increasing. As systems continue to grow in complexity and size, the risks seem to grow accordingly. As a result, ever greater reliance is placed on the omniscience and omnipotence of system administrators. Also, our adversaries are becoming much more agile and are capable of becoming much more aggressive. As a consequence, much greater discipline is required to achieve the necessary goals. This report attempts to characterize what is needed in terms of increased awareness and new approaches for the future.
1. Out of clutter, find simplicity.
2. From discord, find harmony.
3. In the middle of difficulty lies opportunity.
Albert Einstein, three rules of work
The primary goal of this project is to significantly advance the state of the art in obtaining highly survivable systems and networks, whereby distributed systems and networks of systems are considered in their totality as systems of systems, and as networks of networks -- rather than more conventional approaches that focus only on selected properties of certain subsystems or modules in isolation.
To accomplish that goal in this report, Chapter 2 addresses a broad spectrum of threats to survivability. Chapter 3 considers the overarching survivability requirements necessary to surmount those threats, and also considers the subordinate requirements on which survivability ultimately depends -- including reliability, availability, security (confidentiality, integrity, defense against denials of service and other types of misuse), performance, in the presence of accidental and malicious actions and malfunctions of software and hardware. Chapter 4 then identifies fundamental deficiencies in the technology available today, and Chapter 5 makes recommendations for how to overcome those deficiencies. Subsequent chapters address guidelines for developing and rapidly configuring highly survivable systems and networks, including the presentation of generic classes of architectural structures and some specific types of systems. Appendix A considers how the contents of this report might find their way into an educational curriculum.
Despite the quoted dictum of Albert Einstein at the beginning of this chapter, we observe that general-purpose systems and networks that must be highly survivable are not likely to be simple -- unless they are seriously trivialized. The nature of the problem is intrinsically complex: experience shows that many vulnerabilities are commonplace, and not easy to avoid; the potential threats are very broadly based; complexity is often beyond the scope of a small and closely knit development team; management is often unaware of the complexities and their implications. Consequently, the approach of this report is to confront the challenge in its full generality, rather than merely to carve out a simply manageable small subset. Remember the following quote, which is also very pithy:
Everything should be as simple as possible -- but no simpler.
Albert Einstein 1
Recognizing the complexity inherent in satisfying any realistic set of survivability requirements, we have chosen to consider the very difficult fully general problem of achieving highly survivable systems and networks subject to the widest spectrum of threats. By tackling the general problem, we believe that much greater insight can be gained and that the resulting approaches can look farther into the future. In this sense, we believe that there is a significant opportunity in the face of the intrinsic difficulties.
Basic concepts are identified and defined here that are used throughout the report, including survivability, security, reliability, performance, trustworthiness, dependability, assurance, mandatory policies, composition, and dependence. Section 1.3 introduces the notion of compromisibility.
For the purposes of this report, survivability is the ability of a computer-communication system-based application to satisfy and to continue to satisfy certain critical requirements (e.g., specific requirements for security, reliability, real-time responsiveness, and correctness) in the face of adverse conditions. Survivability must be defined with respect to the set of adversities that are supposed to be withstood. Types of adversities might typically include hardware faults, software flaws, attacks on systems and networks perpetrated by malicious users, and electromagnetic interference.2 Thus, we are seeking systems and networks that can prevent a wide range of systemic failures as well as penetrations and internal misuse, and can also in some sense tolerate additional failures or misuses that cannot be prevented.
As currently defined in practice, requirements in use today for survivable systems and networks typically fall far short of what is really needed. Even worse, the currently available operating systems and networks fall even farther short. Consequently, before attempting to discuss survivable systems, it is important to establish a comprehensive set of realistic requirements for survivability (as in Chapter 3). It is also desirable to identify fundamental gaps in what is currently available (as in Chapter 4).
Given a well-defined set of requirements, it is then important to define a family of reusable interoperable baseline system and network architectures that can demonstrably attain those requirements -- with the goals of enhancing the procurement, development, configuration, assurance, evaluation, and operation of systems and networks with critical survivability requirements.
A preliminary scoping of the general survivability problem was suggested by a 1993 report written for the Army Research Laboratory (ARL), Survivable Computer-Communication Systems: The Problem and Working Group Recommendations [29]. That report outlines a comprehensive multifunctional set of realistic computer-communication survivability requirements and makes related recommendations applicable to U.S. Army and defense systems.3 It assesses the vulnerabilities, threats, and risks associated with applications requiring survivable computer-communication systems. It discusses the requirements, and identifies various obstacles that must be overcome. It presents recommendations on specific directions for future research and development that would significantly aid in the development and operation of systems capable of meeting advanced requirements for survivability. It has proven to be useful to ARL as a baseline tutorial document for bringing Army personnel up to speed on system vulnerabilities and basic concepts of survivability. It remains timely. Some of its recommended research and development efforts have still not been carried out, and are revisited here.
The current technical approach is strongly motivated by a collection of highly disciplined system-engineering and software-engineering concepts that can add significantly to the generality and reusability of the results, as well as having specific applicability to Army developments. Above all, our approach here stresses the importance of sound system and network architectures that seriously address the necessary survivability requirements. This approach entails several basic concepts that are considered in the following subsections.
The following three bulleted items consider three types of infrastructures: (1) the critical national infrastructures, (2) information infrastructures such as the Internet, or whatever it may evolve into (a National Information Infrastructure, or a Global Information Infrastructure, or a Solar-System Information Infrastructure, or perhaps even the Intergalactic Information Infrastructure), and (3) underlying computer systems and networking software.
System attributes that are particularly relevant to the attainment of survivability include the following.
What is immediately obvious is that close interrelationships exist among the various requirements. For example, consider the various forms of availability. Availability is clearly a security requirement in defending against malicious attacks. It is clearly a reliability requirement in defending against hardware malfunctions, unanticipated software flaws, environmental causes, and acts of God. It is also a performance issue, in that adequate availability is essential to maintaining adequate performance (and conversely, adequate performance can be essential to maintaining adequate availability, as noted above).
Whereas it is conceptually possible to consider these different manifestations of availability as separate requirements, this is very misleading -- because they are closely coupled in the design and implementation of real systems and networks. As a consequence, we stress the notion of architectures that address these seemingly different requirements in an integrated way that permits the realization of different requirements within a common structure. This is pursued further in Section 3.1.
Fundamental to this report are the notions of trustworthiness, dependability, and assurance.
Trustworthiness is particularly relevant in situations where there are critical requirements, that is, where dependence on the trustworthiness of specific entities is crucial to the overall behavior of a system or network in the large -- particularly with respect to survivability, security, and reliability. In the fault-tolerance community, dependability tends to be a measure of how well the specified fault-tolerance requirements are met, although recent usage is generalizing that to other requirements.
A careful distinction is made here between trust and trustworthiness. Trust is something you attribute to a system entity, whether that entity is trustworthy or not. A trustworthy entity is one that deserves to be trusted.
In general usage in the literature, a trusted system is one that must be trusted in order for applications using the system to behave properly. Ideally, trusted systems should be trustworthy, although that is often not the case. For example, the notion of trusted computing bases (Section 7.2) is really concerned with trustworthiness of components that, because of their functionality, have to be trusted -- and that therefore must be trustworthy.
The foregoing concepts -- survivability, security, reliability, and performance -- need to be implemented in such a way that the desired properties can be achieved dependably. Defensive measures include establishment of appropriate requirements, good system design that is consistent with the requirements, good system development and coding practice including the use of modern software engineering and sound programming languages and demonstrations that implementations are consistent with their designs, and operational procedures that maintain the integrity of design and implementation despite ongoing debugging and maintenance -- and potential misuse.
Various other attributes are also highly desirable in ensuring dependable survivability.
These concepts are considered further in Sections 7.1 and 7.2.
Whereas we have chosen a framework in which survivability depends on security, reliability, and performance attributes (for example), manifestations of survivability, security, and reliability exist at many different layers of abstraction. Although the survivability of an enterprise may depend on the underlying security and reliability, the security and reliability at a particular layer may in turn depend to some extent on the survivability of a lower layer. For example, the survivability of each of the eight critical national infrastructures considered by the PCCIP depends to some extent on the survivability and other attributes of the underlying computer-communication infrastructures. Similarly, the survivability of a given computer-communication infrastructure may typically depend to considerable extent on the survivability of the electric power and telecommunications infrastructures. In part, this is a consequence of the fact that the definitions used here are (necessarily) somewhat overlapping; in part, it is also a recognition of the fact that each abstract layer has its own set of requirements that must be translated into subrequirements at lower layers.
One of the primary goals of the present work is to identify the ways in which the various properties and their enforcing implementations depend on one another, at various layers of abstraction and across different abstractions at given layers.
This report in no way attempts to be a definitive self-contained treatise on everything that needs to be known to procurers and developers of highly survivable systems. Rather, it attempts to identify and use constructively some of the fundamental concepts upon which such systems can be produced. Extensive further background on computer system trustworthiness can be found in National Research Council reports, Computers at Risk [72] and the more recent Trust in Cyberspace [345]. (See also [109] for a recent NRC study on research needs.) Two valuable volumes on cryptography's role in trustworthy systems and networks are the National Research Council CRISIS report Cryptography's Role in Securing the Information Society [84] and Bruce Schneier's Applied Cryptography [347]. A realistic assessment of the risks of improperly embedded strong crypto is found in Schneier's subsequent book [348], Secrets and Lies: Digital Security in a Networked World.
Research efforts have typically considered simple compositions of modules, such as unidirectional serial connections or perhaps call-and-return semantics. (Section 5.8 discusses some of these.) However, the existing research is far from realistic.
The concept of generalized composition [251] used here includes composition of subsystems with mutual feedback, hierarchical layering in which a collection of modules forms a layer that can be used by higher layers as in the Provably Secure Operating System (PSOS) [102, 246, 247, 260], layering achieved through program modularity [45], and networked connections involving client-server architectures, gateways, unidirectional and bidirectional firewalls and guards, encryption, and other components. Relevant approaches include [371].
In this project, we consider generalized composition as it relates to the composed subsystems. We believe that this approach to composition is more appropriate to the intended large-scale distributed and networked architectures than the primarily theoretical contemporary work on model composition and policy composition (although that work is logically subsumed under the present approach).
In 1974, Parnas [279] characterized a variety of depends upon relations. An important such relation is Parnas's depends upon for its correctness, whereby a given component is said to depend upon another component in the sense that if the latter component does not meet its requirements, then the former may not meet its requirements. Neumann [251] has revisited the notion of dependence, making a distinction between the Parnas relation depends upon for correctness and a generalized sense of dependence in which greater trustworthiness can be achieved despite the presence of less trustworthy components, thereby avoiding having to depend completely on components of unknown or uncertain trustworthiness. To avoid having to say "depends upon in the sense of generalized dependence", we abbreviate that generalized relation as simply depends on.
The following enumeration gives various paradigms under which trustworthiness can actually be enhanced, providing examples of how the generalized dependence relation depends-on differs from the conventional depends-upon relation. In each of these cases, the resulting trustworthiness tends to be greater than that of the constituent components. The list is surprisingly long, and may help to illustrate the power of the notion of generalized dependence. (Although particular mechanisms may fall into multiple types, these types are intended to represent the diverse nature of mechanisms having the characteristics of generalized dependence.)
Each of these paradigms demonstrates techniques whereby trustworthiness can be enhanced above what can be expected of the constituent subsystems or transmission media. By generalizing the notions of dependence and trustworthiness, and judicious use of some of these techniques, we seek to provide a unifying framework for the development of survivable systems.
Dependence on components and information of unknown trustworthiness is a particularly serious potential problem. (See Sections 2.1.1 and 2.1.2.)
Dependable clocks (Byzantine or otherwise) provide a particularly interesting challenge. Lincoln, Rushby, and others [181] provide an elegant detailed example of generalized dependence. They have analyzed a three-layered model consisting of (1) clock synchronization [332], (2) Byzantine agreement [179, 180], and (3) diagnosis and removal of faulty components [180]. They also exhibit formal verifications for a variety of hybrid algorithms [180] that can greatly increase the coverage of misbehaving components. This three-layered integration of separate models and proofs is of considerable practical interest, as well as illustrative of forefront uses of formal methods.
An example of generalized dependence relating to clock drift is given by Fetzer and Cristian [104] in developing fault-tolerant hardware clocks out of commercial off-the-shelf (COTS) components, at least one of which is a GPS receiver. A formal analysis of a time-triggered clock synchronization approach is given by [299].
The basic approach of this project considers within a common framework many different generalized-dependence mechanisms that are capable of enhancing trustworthiness, enabling the resulting functionality to be inherently more trustworthy than otherwise might be warranted by consideration of only its constituent components.
Ultimately, overall system survivability may depend on (in the sense of generalized dependence noted above) the security, integrity, reliability, availability, and performance characteristics of certain critical portions of the underlying computer-communication infrastructures. In this report, our notion of survivability explicitly includes this context of generalized dependence.
Compromises from outside, from within, or from below (see Section 1.3 and [250, 251, 267]), whether malicious or not, can subvert survivability unless prevented or ameliorated by the architecture, its implementation, and the operational practice. Unfortunately, compromises from outside (e.g., externally, originating from higher layers of abstraction or from other entities at the same layer of abstraction, or from supposedly security-neutral applications) often can lead to compromises from within (affecting the implementation of a particular mechanism) or from below (subverting a mechanism by tampering with its underlying dependent components). One of the fundamental challenges addressed here is to be able to design, implement, and operate survivable systems despite the presence of components, information, and individuals of unknown trustworthiness -- as well as saboteurs (e.g., cyberterrorism [302]), and thereby to prevent, defend against, or at least detect attempted compromises from outside, within, or below. This is in essence what we mean by survivability -- in the context of generalized dependence on potentially unknown entities. For example, a particularly difficult challenge is to ensure that the embeddings of sound cryptographic algorithms cannot be compromised because of inherent weaknesses in the underlying computer-communication infrastructures (e.g., hardware, microcode, operating systems, database management, and networking) -- as discussed in [249].
Survivability is an emergent property of the overall systems and networks. That is, it is not definable and analyzable in the small, because it is the consequence of the composition of the subtended functionality; it must be considered in the large. In other words, it is not a property that can be identified with any of the constituent components. Ideally, it should be derivable in terms of properties of the constituent functionality on which it depends, as described in the 1970s work of Robinson and Levitt [322] on the SRI Hierarchical Development Methodology (HDM) as part of the PSOS effort.4 In practice, it may not be so derivable, as in the case of covert channels that arise only because of module composition.
Stephanie Forrest in her introduction to the 1991 CNLS proceedings [106], Nancy Leveson [173], Heather Hinton [127, 128], Zakinthinos and Lee [394], and D.K. Prasad [306] provide some background on emergent properties; Zakinthinos and Lee define an emergent property as one that its constituent components do not satisfy. Prasad draws on measurement theory and decision analysis [307] to show that such properties are not compositional and also that such properties are not `absolute' -- different stakeholders may have different ideas about the meaning of the property. Her thesis work also presents the method of multi-criteria decision making (in a specific framework) as an approach for the measurement (on a sound theoretical basis) of such properties. Hinton [128] observes that undesirable emergent behavior is often the result of incomplete specification, and can be formally analyzed.
The notions of multilevel security [32, 33, 34, 35, 36], multilevel integrity [42], and multilevel availability [267] characterize hierarchical mandatory policies for confidentiality, integrity, and availability, respectively. In multilevel security (MLS), information is not permitted to flow from one entity to another entity that has been assigned a lower security level. In multilevel integrity (MLI), no entity is permitted to depend upon an entity that has been assigned a lower integrity level. In multilevel availability (MLA), no entity is permitted to depend on an entity that has been assigned a lower availability level.
Although it has been the subject of considerable research in security policies and kernelized system architectures, and highly touted by the Department of Defense (see Chapter 6), multilevel security has remained very difficult to achieve in realistic systems and networks. This is due to many factors, including inadequacies in the DoD criteria, an unwillingness of commercial system providers to develop systems, and an unwillingness of non-DoD system acquirers to consider such systems. Architectural alternatives are considered in Chapter 7.
Strict multilevel integrity is thought to be awkward to enforce in practical systems, because high-integrity users and processes often depend on editors, compilers, library routines, device drivers, and so on, that are typically not necessarily trustworthy and therefore are risky to depend upon. However, that is precisely the fundamental integrity problem in most system architectures. The implicit web of trust should force those utility functions to be at least as trustworthy with respect to integrity, because they must all be considered within the perimeter of trustworthiness. The notion of generalized dependence is one way of working within that constraint without either sacrificing the power of the basic concepts or of introducing new vulnerabilities that result from informal deviations from strict interpretations.
In this report, we consider the conceptual use of this kind of mandatory basis for survivability. Strictly speaking, this would lead to a lattice-based mandatory policy for multilevel survivability that directly imitates the MLS, MLI, and MLA policies. For simplicity, we refer to this policy as simply multilevel survivability (MLX). In an oversimplified formulation of the multilevel survivability policy, no system or network entity is allowed to depend on an entity that has been assigned a lower survivability level (unless an explicit generalized-dependence mechanism is established that permits the use of mechanisms of lower trustworthiness, as illustrated in Section 1.2.5). These concepts are considered in this report to include generalized dependence.
For descriptive purposes, we implicitly assume the possibility of compartments in each of these policies (MLS, MLI, MLA, and MLX), although we describe the policies in terms of levels (without categories). Because of the compartments (familiar to afficianados of MLS and MLI), the ordering on the levels and compartments generates a mathematical lattice in each instance. Thus, when we refer to mandatory policies in this context, we imply lattice-based policies rather than just completely ordered levels (without compartments).
In the absence of generalized dependence, strict MLX ordering would most likely suffer the same kind of problems that arise in the practical use of strict MLI -- namely, the realization that enormous portions of any given distributed system must be of high integrity and high survivability. The notion of generalized dependence therefore allows the strict partial ordering to be relaxed locally whenever it is possible to achieve greater trustworthiness out of less trustworthy components, as illustrated in Section 1.2.5 -- without relaxing it in the large.
For readers who shudder at the complexities and inconveniences introduced by multilevel policies, we hasten to add that the MLX property is considered only as a structural organizing concept rather than as an explicit goal of design and implementation. Furthermore, even if MLX were interpreted seriously, there is always a likelihood that the levels and compartments might be set up in such a way that there would be a fundamental conflict among the MLS, MLI, MLA, and MLX constraints that would prevent expected results from happening. Consequently, MLX is introduced only to encourage the intuitive design of systems in which we avoid unnecessary dependence on components that are inherently less survivable (in the sense of generalized dependence).
This initial discussion represents a first approximation to what is actually needed. In Chapter 7, we address the possible conflicts among the subrequirements of survivability in the context of generalized dependence.
To illustrate the importance of dependence on properties of underlying abstractions, consider the necessity of depending on a life-critical system for the protection of human safety.5 In such a system, safety ultimately depends upon the confidentiality, integrity, and availability of both the system and its data. It may also depend on information survivability. It may further depend upon component and system reliability, and on real-time performance. It also usually depends upon the correctness of much of the application code. In the sense that each layer in a hierarchical system design depends upon the properties of the lower layers, the way in which trusted computing bases are layered becomes important for developing dependably safe systems -- particularly in those cases in which the generalized depends on relation can be used more appropriately instead of depends upon to accommodate an implementation based on less trustworthy components.
The same dependence situation is true of secure systems, in which each layer in the abstraction hierarchy (e.g., consisting of a kernel, a trusted computing base for primitive security, databases, application software, and user software) must enforce some set of security properties. The properties may differ from layer to layer, and various trustworthy mechanisms may exist at each layer, but the properties at a particular layer are derivable from lower-layer properties.
In the security context, many notions of compromise exist. For example, compromise might entail accessing supposedly restricted data, inserting unvalidated code into a trusted environment, altering existing user data or operating-system parameters, causing a denial of service, finding an escape from a highly restricted menu interface, or installing or modifying a rule in a rule-base that results in subversion of an expert system.
There is an important distinction between having to depend on lower-layer functionality (whether it is trustworthy or not) and having some meaningful assurance that the lower-layer functionality is actually noncompromisible under a wide range of actual threats. Noncompromisibility is particularly important with respect to security, safety, and reliability.
Potentially, a supposedly sound system could be rendered unsound in any of three basic ways:
Each of these situations could be caused intentionally, but could also happen accidentally. (For descriptive simplicity, a user may be a person, a process, an agent, a subsystem, another system, or any other computer-related entity.)
The distinctions among these three modes tend to disappear in systems that are not well structured, in which inside and outside are indistinguishable (as in systems with only one protection state), or in which outside and below are merged (as in flat systems that have no concept of hierarchy). In addition, compromises from outside may subsequently enable compromises from within, and compromises from outside or within may subsequently enable compromises from below. The distinctions are also murky in cases of emergency operations. Furthermore, an egregious process whereby vendors can disable software remotely is discussed in Section 2.4.
Certain attack modes may occur in any of these forms of compromise. For example, consider the following Trojan-horse perpetrations, which can take place in each form.
Table 1: Illustrative Compromises
Layer of Compromise Compromise Compromise abstraction from outside: from within: from below: Needs exogirding Needs endogirding Needs undergirding Outside Acts of God, Chernobyl-like environment earthquakes, disasters caused lightning, etc. by users or operators User Masqueraders Accidental mistakes; Application system outage Intentional misuse or service denial Application Penetrations of Programming errors Application (e.g., DBMS) application service in application code undermined within integrity operating systems (OSs) Middleware Penetration of Trojan horsing of Subversion of middleware Web and DBMS Web and DBMS from OS or network servers servers operations Networking Penetration of Trojan horsing of Capture of crypto routers, firewalls; network software keys within the OS; Denials of service Exploitation of lower protocol layers Operating Penetrations of OS by Flawed OS software; OS undermined from system unauthorized users Trojan-horsed OS; within hardware: Tampering by faults exceeding fault privileged tolerance; hardware processes flaws or sabotage Hardware Externally generated Bad hardware design Internal power electromagnetic or and implementation; irregularities other interference; Hardware Trojan horses; External power- Unrecoverable faults; utility glitches Internal interference Inside Malicious or Internal power supplies, environment accidental acts tripped breakers, UPS/battery failures
Table 1 summarizes some properties whose nonsatisfaction could potentially compromise system behavior, by compromising confidentiality, integrity, availability, real-time performance, or correctness of application software, either accidentally or intentionally. To illustrate such compromises, the table also indicates possible compromises -- whether they involve modification (tampering) or not -- that can occur from outside, from within, or from below, for each representative layer of abstraction. The distinctions are not always precise: a penetrator may compromise from outside, but once having penetrated, is then in position to compromise from below or from within. Thus, one type of compromise may be used to enable another. For this reason, the table characterizes only the primary modes of compromise. For example, a user entering through a resource access control package such as RACF or CA-TopSecret, or through a superuser mechanism, and gaining apparently legitimate access to the underlying operating system may then be able to undermine both operating-system integrity (compromise from within) and database integrity (compromise from below if through the operating system), even though the original compromise is from outside. Similarly, a software implementation of an encryption algorithm or of a cryptographic check sum used as an integrity seal can be compromised by someone gaining access to the unencrypted information in memory or to the encryption mechanism itself, at a lower layer of abstraction. A user exploiting an Internet Protocol router vulnerability may initially be able to compromise a system from within the logical layer of its networking software, but subsequently may create further compromises from outside or below. The Thompson compiler Trojan horse is a particularly interesting case, because it may not normally be thought of as compromise from below if the compiler is not understood to be something that is depended upon for its correct behavior. Indeed, it is a very bad policy to use an untrustworthy compiler to generate an operating system, and therefore the compiler must be considered "below" (or else the dependence must be considered as a violaton of layered trustworthiness, as in MLX). Indeed, the entire software development process is a huge opportunity for compromising the integrity of the resulting system (intentionally or accidentally).
From the table, we observe that a system may be inherently compromisible, in a variety of ways. The purpose of system design is not to make the system completely noncompromisible (which is impossible), but rather to provide some assurance that the most likely and most devastating compromises are properly addressed by designs, architectures, development processes, and operational practices, and -- if compromises do occur -- to be able to determine the causes and effects, to limit the negative consequences, and to take appropriate actions. Thus, it is desirable to provide underlying mechanisms that are inherently difficult to compromise, and to build consistently on those mechanisms. On the other hand, in the presence of underlying mechanisms that are inherently compromisible, it may still be possible to use Byzantine-like strategies to make the higher-layer mechanisms less compromisible. However, flaws that permit compromise of the underlying layers are inherently risky unless the effects of such compromises can be strictly contained.
Protection against the three forms of compromise noted in Section 1.3 -- compromise from outside, compromise from within, and compromise from below -- are referred to in this report as exogirding, endogirding, and undergirding, respectively -- that is, providing outside barrier defenses, internal defenses, and defenses that protect underlying mechanisms, respectively.6
In general, all three types of protection are necessary. Various approaches are considered in Chapters 5, 7, and 8. For the purposes of this chapter, just a few illustrative examples are given here, relating to a few of the layers of abstraction shown in Table 1. As indicated by this summary, some of the techniques are quite different from one case to another, although other techniques are more generically applicable.
Some of the many stages of system development and use during which risks may
arise are listed below, along with a few examples of what might go wrong (and,
in most cases, what has gone wrong in the past). This list summarizes
some of the main threats.
Section 1.6 gives examples of specific illustrative cases.
Problems in the system development process involve people at each stage, and are illustrated by the following examples:
Problems in system operation and use involve people and external factors, and are illustrated by the following examples:
The last subcategory -- intentional misuse -- represents a particular worrisome area of concern and is considered in Section 2.1.
We consider here just a few illustrative problems that have been encountered in the past, suggesting the rather pervasive nature of the survivability problem -- with many diverse causes and effects.
The first seven items listed below involved massive outages triggered accidentally by local events, each of which compromised overall system and network survivability. The eighth was triggered by a single human error, but the effects propagated throughout the San Francisco Bay Area. The ninth involved a local outage that was quickly corrected, but whose after-effects continued to propagate for many hours. These cases involved human factors as well as other causes.
The remaining cases noted here are examples of other types of accidental survivability problems, although less widespread in their resulting effects.
Next, we consider a few cases attributed to malicious acts.
In addition, a U.S. General Accounting Office study uncovered some rather egregious security vulnerabilities in the Web site of the Environmental Protection Agency. When threatened with exposure of those vulnerabilities by an environmentally unsympathetic Congressman, the EPA chose to remove its Web site from the Net altogether (RISKS-20.77).
There was also a report in Federal Computer Week that a DoD bloodtype database had been subverted and bloodtype data altered (RISKS-19.97); however, that report was subsequently corrected: no such penetration had occurred, although a red team had identified the possibility of such an attack and contemplated its possible effects (RISKS-20.02). The fallacious report apparently did cause the Pentagon to reconsider what information is put on its Web sites.
References to these and many other similar cases of nonsurvivable systems
and networks can be found in Neumann's RISKS
book [250] and in the on-line archives of the Risks
Forum at
http://catless.ncl.ac.uk/Risks/, where
you can browse and search through RISKS issues. A compendium of short,
mostly one-liner, descriptions of cases ([256] is
browsable on-line at
http://www.csl.sri.com/neumann/illustrative.html
and in ftp form for compact printing
ftp://ftp.csl.sri.com/pub/users/neumann/illustrative.ps
and
ftp://ftp.csl.sri.com/pub/users/neumann/illustrative.pdf.
(Other known cases have been reported informally, but not documented publicly.) Some cases of nonsurviving systems are attributable to software flaws introduced by system design, by system software development, or by maintenance, at various points in the system life cycle. Some were due to hardware, others to environmental factors such as electromagnetic radiation, others simply to human foibles.
Malicious system misuse is a very serious potential problem (especially when it can result in system and network collapse), although most of the penetration efforts recorded to date were attacks on computer systems themselves rather than on critical applications that used computers. Nevertheless, serious security vulnerabilities exist in many mission-critical systems, many of which could result in loss of survivability.
With all the furor over penetrations of Web sites, denial-of-service attacks, and propagating Trojan horses in e-mail, deeper issues seem lost in the shuffle. In the case of the penetrations and distributed denial-of-service attacks, it is obvious that operating system security and networking robustness are inadequate. In the e-mail cases, the vulnerabilities exploited in the MS Word macro virus in Microsoft Outlook and Outlook Express have been around for a long time and are likely to be around for a long time. Although some palliative fixes are available, the fundamental problems remain. For example, filters deleting e-mail with "Subject: Important Message from ..." are only partially useful, in light of variant versions of Melissa with Subject: lines that are different or even blank. The same problem repeated itself a year later with ILOVEYOU and its subsequent clones. The basic system infrastructure is incapable of adequately protecting itself against all kinds of misuses, and this particular exploit is just another reminder that many folks need to wake up. The situation could have been much worse, but unfortunately many of those who depend on systems that are inherently inadequate do not get the proper messages when the situation is not a terrible disaster. On the other hand, even if we were to have terrible disasters, it apparently would not be enough. Many of the constructive lessons that should have been learned from Robert Tappan Morris's Internet Worm in 1988 and subsequent events are still unlearned. (See my 1997, 1999, and 2000 testimonies for the U.S. House Judiciary Committee at http://www.csl.sri.com/neumann/house97.html, http://www.csl.sri.com/neumann/house99.html, http://www.csl.sri.com/neumann/house00.html, respectively, which discuss the amazing lack of progress from one year to the next. Written answers to Representatives' questions on the 1997 testimony are also on-line: http://www.csl.sri.com/neumann/house97.ans.)
One of the major lessons involves the risk of monocultures, that is, putting all your eggs in one basket -- particularly when that basket is inherently vulnerable. A second lesson is that when a potentially dangerous vulnerability is exploited in a relatively harmless way, proactive measures should be taken to avoid much greater damage in the future. The Melissa and ILOVEYOU PC viruses both exploited the scripting capabilities of Microsoft Outlook. The latter case should have been no surprise, but the damage could have been much greater. A third lesson is that we have still not seen enormously destructive PC viruses, and have only begun to find polymorphic pest programs that can transform themselves continually in order to hinder detection.
Breakdowns in system survivability are often attributed to either security problems or reliability problems. However, there is an interesting crossover between the two types of problems, whereby causes and effects may be related and in some cases intermixed. The following enumeration suggests this coupling. It illustrates the distinctions and similarities between the two types, and gives a preliminary view of some of the interdependencies.
In time of crisis, there can be uncertainty over whether a particular survivability problem is related to security or to reliability, availability, and fault tolerance.
Furthermore, in certain cases it may not be evident whether a particular attack was natural or human related -- and if human, whether accidental or intentional, malicious or otherwise. Indeed, there is long-standing evidence that intruders ("crackers") have had access to the telephone switches, and could have caused results otherwise attributed to system problems. As noted above, the 15 January 1990 AT&T outage may actually have been triggered by intruders, albeit accidentally. There is also an unverified statement made by an FBI agent during a talk at the University of California at Davis to the effect that the 2 July 1997 West Coast power outage involved some maliciously caused events.
As further examples of the fuzzy crossover between reliability and security - although directed more toward survivability of integrity requirements than toward survivability per se -- there have been numerous cases of suspicious activities involving computers used in elections. In one case in particular, the results of the preliminary test processing were left undeleted, and actually would have caused the wrong winner to be elected, had an anomaly not been detected. Although this error was eventually diagnosed and corrected, the claim was of course made that this was an accident. How do you know it was not intentional?
The foregoing discussion also applies to performance degradations as well as complete outages. The evident heterogeneity of causes and effects suggests that systems should be developed to anticipate a broader class of threats -- not just to narrowly address threats to security, or to reliability, or to performance, but rather to address the necessary requirements in the same context.
An obvious conclusion of this discussion is that systems should be designed to be survivable, to withstand both accidental malfunctions and intentionally caused outages or other deviations from desired behavior. Survivability in turn requires a variety of further requirements, for example, relating to security, reliability, and robustness of components, networks, algorithms, implementations, and so on.
Numerous vulnerabilities, threats, and risks are encountered in attempting to develop, operate, and maintain systems with stringent survivability requirements. All these sources of adversity can result in system and application survivability being undermined. The sections of this chapter consider threats to security, reliability, and performance, respectively. Whereas it is convenient to think of these types of threats as independent of one another, they are in fact related in various ways. However, what is most important is that the totality of threats must be addressed by the system requirements and by the system architectures that presume to address those requirements.
Security is mostly a superstition.9
Helen Keller
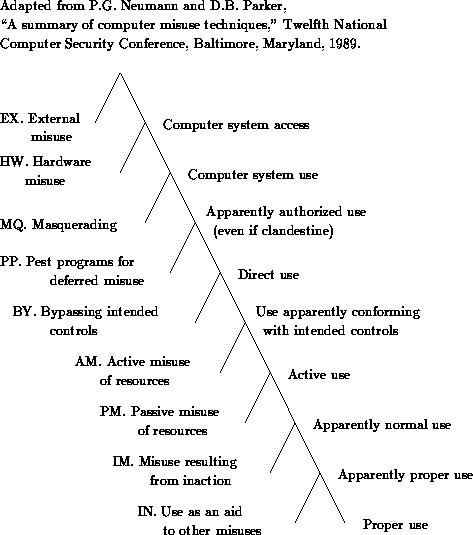
Malicious attacks can take many forms, summarized in Table 2 according to a classification scheme shown in Figure 1, based on earlier work of Neumann and Parker [264]. For visual simplicity, the figure is approximated as a simple tree. However, it actually represents a system of descriptors rather than a taxonomy in the usual sense, in that a given misuse may involve multiple techniques within several classes.
The order of categorization depicted is roughly from the physical world to the hardware to the software, and from unauthorized use to misuse of authority. The first class includes extrinsic misuses that can take place without any access to the computer system. The second class concerns system misuse and typically requires some involvement with computer hardware or software. Two types in this class are eavesdropping and interference (usually electronic or electromagnetic, but optical and other forms are also possible). Another major type of this class involves denial-of-service attacks that can be committed remotely without any need for authorized access. The third class includes masquerading in a variety of forms. The fourth includes the establishment of deferred misuse, for example, the creation and enabling of a Trojan horse (as opposed to subsequent misuse that accompanies the actual execution of the Trojan-horse program -- which may show up in other classes at a later time), or other forms of pest programs discussed below. The fifth class involves bypass of authorization, possibly enabling a user to appear to be authorized -- or not to appear at all (that is, to be invisible to the audit trails). The remaining classes involve active and passive misuse of resources, inaction that might result in misuse, and finally misuse that helps in carrying out additional misuses (such as preparation for an attack on another system or use of a computer in a criminal enterprise).
The main downward sloping right-hand diagonal line in Figure 1 indicates typical steps and modes of intended use of computer systems. The leftward branches all involve misuse, while the rightward branches represent potentially acceptable use -- until a leftward branch is taken. (Each labeled mode of usage along the main-diagonal intended-usage line is the antithesis of the corresponding leftward misuse branch.) Every leftward branch represents a class of vulnerabilities that must be defended against -- that is, either avoided altogether or else detected and recovered from. The means for prevention, deterrence, avoidance, detection, and recovery typically differ from one branch to the next. (Even inaction may imply misuse, although no abusive act of commission may have occurred.)
The ordering used in Figure 1 and Table 2 is roughly upside down from the natural layering used in Tables 1 and 4 -- except for the Extrinsic Misuse category, which is at the top. This order helps to maintain the sense of the cumulatively increasing binary-tree choices at each layer and the successful choices down the right-sloping diagonal of Figure 1.
It must be noted that no taxonomy is perfect. There are always fuzzy boundaries and overlaps. Besides, many actual perpetrations involve multiple types of misuse. No claim is made for this particular representation. However, the categories shown here are useful, recurring frequently in the discussion throughout this report.
Two classes of misuse techniques are of primary interest here, namely, bypasses of authority (trapdoor exploitations and authorization attacks) and preplanned pest programs such as Trojan horses, PC viruses, and worms, with effects including time bombs, logic bombs, and general havoc. However, several other forms are important in the present context, and these are also discussed.10
Figure 1: Classes of Computer Misuse Techniques
Table 2: Types of Computer Misuse
Extrinsic misuse (EX) 1. Visual spying: observation of keystrokes or screens 2. Misrepresentation: social engineering, deception 3. Physical scavenging: dumpster-diving for printout System misuse (HW) 4. Logical scavenging: examining discarded or stolen media 5. Eavesdropping: electronic or other data interception 6. Interference: electronic or other jamming 7. Physical attack on, or modification of, equipment or power 8. Physical removal of equipment and storage media 9. Remote denials of service without needing system access Masquerading (MQ) 10. Impersonation: false identity external to computer systems 11. Piggybacking attacks on communication lines, workstations 12. Playback and spoofing attacks, particularly IP spoofing 13. Network weaving to mask physical whereabouts or routing 14. Denials of service with spoofed identity Pest programs (PP) -- setting up opportunities for further misuse 15. Trojan-horse attacks (including letter bombs) 16. Logic bombs (a form of Trojan horse, including time bombs) 17. Malevolent worm attacks, acquiring distributed resources 18. Virus attacks, attaching to programs and replicating Bypassing authentication or authorization (BY) 19. Trapdoor attacks, from any of a variety of sources: a. Improper identification and authentication b. Improper initialization or allocation c. Improper termination or deallocation d. Improper run-time validation e. Naming flaws, confusions, and aliases f. Improper encapsulation: exposed implementation detail g. Asynchronous flaws: e.g., time-of-check to time-of-use anomalies h. Other logic errors 20. Authorization attacks, for example, password cracking, token hacking Active misuse of authority (AM) (writing, using, with apparent authorization) 21. Creation, modification, use, service denials (includes false data entry) 22. Incremental attacks (e.g., salami attacks) 23. Denials of service requiring authorization Passive misuse of authority (PM) (reading, with apparent authorization) 24. Browsing randomly or searching for particular characteristics 25. Inference and aggregation (especially in databases), traffic analysis 26. Covert channel exploitation and other data leakage 27. Misuse through inaction (IM): willful neglect, errors of omission 28. Use as an indirect aid for subsequent misuse (IN): off-line preencryptive matching, factoring large numbers, autodialer scanning.
Common cases of unauthorized access can result from system and usage flaws (e.g., trapdoors that permit devious access paths) such as the following [245]:
Password attacks are a particularly insidious subclass of trapdoor attacks and may involve, for example
A Trojan horse is typically a computer program that surreptitiously contains functionality that contains a hidden source of risk, with effects of varying seriousness. A logic bomb is a Trojan horse whose effects are triggered by the occurrence of some logical event. A time bomb is a logic bomb whose logical trigger is based on time. A virus is a program that can iteratively infect other programs with copies of itself. Personal computer viruses tend to propagate as a result of manual actions such as shared diskettes; mainframe viruses in theory could propagate automatically, but are rare. A worm is a program capable of executing pieces of itself simultaneously, often remotely. These are discussed further below.
Anything that appears innocently as data but whose execution can be triggered surreptitiously represents a serious risk. Web browers present numerous opportunities for the execution of Trojan horses on your own machine when your browser downloads an applet, because the applet typically executes with all or many of your execution privileges. This is a problem with Java applets, ActiveX components, and browser plug-ins. Mobile code can cause some particularly nasty security problems, especially if it originates from an untrustworthy site -- where any Web browser may access a site that houses a stable full of Trojan horses or permit other types of intrusions [103, 160, 326], unbeknownst to users. (For an incisive account of mobile-code security, see Gary McGraw and Ed Felten's Java security book [200] or preferably its second edition [201].) Many other situations have similar risks. Word Macro viruses and the presence of an executable printing-language interpreter (e.g., for PostScript) offer further opportunities for compromise from outside that can set up compromise from within that result from a Trojan horse that would seem to be ordinary data. Similar opportunities arise in CD-ROMs, zip drives, and other portable storage media, agent software, scripting languages, and e-mail enclosures (such as MIME). This problem is likely to worsen in the presence of real-time audio and video, where enormous security vulnerabilities already exist.
The setting up of these pest programs may actually employ misuses of other classes such as bypasses or misuse of authority, or may be planted via completely normal use, as in a letter bomb. The subsequent execution of the deferred misuses may also rely on further misuse methods. Alternatively, execution may involve the occurrence of some logical event (e.g., a particular date and time, or a logical condition), or may rely on the curiosity, innocence, or normal behavior of the victim. Indeed, because a Trojan horse typically executes with the privileges of its victim(s), its execution may require no further privileges. For example, a Trojan-horse program might find itself authorized to delete all the victim's files. A Trojan-horse letter bomb (with hidden control characters and escape sequences squirreled away in the text) might be harmless unless explicitly read interpretively or otherwise executed; however, if the system permits the transit of such characters, the letter bomb would be able to exploit that flaw and be executed unknowingly by the victim. Several existing systems still permit the interpretation of characters, despite the long-term knowledge of this problem.
In addition to the foregoing two forms of malicious attacks (bypasses and pest programs), various forms of attack are related to the misuse of conferred or acquired authority. Indeed, these are the most common forms of attack in some environments:
Misuse of authority is of considerable concern here because it can be exploited in either the installation or the execution of malicious code, and because it represents a major threat modality. In general, attempts to install and execute malicious code may employ a combination of the methods enumerated above, as well as others external to the computer systems, such as scavenging of discarded materials, visual spying, deception, eavesdropping, theft, hardware tampering, and masquerading attacks -- including playback, spoofing, and piggyback attacks; these are discussed by Neumann and Parker [264]. For example, the Wily Hackers [366, 367] exploited trapdoors, masquerading, Trojan horses to capture passwords, and misuse of (acquired) authority. The Internet Worm [324, 354, 360] attacked four different trapdoors, the debug option of sendmail, gets (used in the implementation of finger), remote logins exploiting .rhost files, and (somewhat gratuitously) a few hundred passwords obtained by selected preencryptive matching attacks. The result was a self-propagating worm with virus-like infection abilities.
The most basic pest-program problem is the Trojan horse, which contains code that when executed can have malicious effects (or even accidentally devastating effects). The installation of a Trojan horse often employs system vulnerabilities, which permit penetration by either unauthorized or authorized users. Furthermore, when executing, Trojan horses may exploit other vulnerabilities such as trapdoors. In addition, Trojan horses may cause the installation of new trapdoors. Thus, there can be a strong interrelationship between Trojan horses and trapdoors. Time bombs and logic bombs are special cases of Trojan horses. Letter bombs are messages that act as Trojan horses, containing bogus or interpretively executable data.
A strict-sense virus, as defined by Cohen [74], is a program that alters other programs to include a copy of itself. Viruses often employ Trojan-horse effects, and the Trojan-horse effects often depend on trapdoors that are either already present or that are created for the occasion. There is a lack of clarity in terminology concerning viruses, with two different sets of usage, one for strict-sense viruses, another for personal-computer viruses. What are called viruses in original usage are usually Trojan horses that are self-propagating without any necessity of human intervention (although people may inadvertently facilitate the spread). What are called viruses in the personal-computer world are usually Trojan horses that are propagated by human action. Personal-computer viruses are rampant, and represent a serious long-term problem (Section 2.1.5). On the other hand, strict-sense viruses (which attach themselves to other programs and propagate without human aid) are a rare phenomenon -- none are known to have been perpetrated maliciously, although a few have been created experimentally.
A worm is a program that is distributed into computational segments that can
execute remotely. It may be malicious, or may be used constructively --
for example, to provide extensive multiprocessing, as in the case of the early
1980s experiments by Shoch and Hupp at Xerox PARC [355]. The
Internet Worm provides
a graphic illustration of how vulnerable some systems are to a variety of
attacks. It is interesting that, even though some of those vulnerabilities
were fixed or reduced, equally horrible vulnerabilities still remain today.
(The argument over whether the Internet Worm was a worm
or a virus is an example of a "terminology war"; its resolution depends on
which set of definitions is used.)
Subtle differences in the types of malicious code are relatively unimportant. Rather than try to make fine distinctions, it is much more appropriate to attempt to defend against the malicious code types systematically, employing a common approach that is capable of addressing the underlying problems. The techniques for an integrated approach to combatting malicious code necessarily cover the entire spectrum, except possibly for certain vulnerabilities that can be completely ruled out -- for example, because of operating environment constraints such as all system access being via hard-wired lines to physically controlled terminals. Thus, generic defenses are more effective in the long term than defenses aimed only at particular attacks. Besides, the attack modes tend to shift with the defenses. For these reasons, it is not surprising that many of the defensive techniques in the system evaluation criteria can be helpful in combatting malicious code and trapdoor attacks (although the criteria at the lower levels do not explicitly prevent such attacks). It is also not surprising that in general the set of techniques necessary for preventing malicious code is very closely related to the techniques necessary for avoiding trapdoors. The weak-link nature of the security problem suggests a close coupling between the two types of attack, and that defense against one type can be helpful in defending against the other type.
Malicious code attacks such as Trojan horses and PC viruses are not adequately covered by the existing system evaluation criteria. The existence of such code would typically never show up in a system design, except possibly for accidental Trojan horses (an exceedingly rare breed). They are addressed primarily implicitly by the criteria and remain a problem even in the most advanced systems (although the threat from external attack can be reduced if those systems are configured and used properly).
Indeed, differences exist among the different types of malicious code
problems, but it is the similarities and the overlaps that are most
important. Any successful defense must recognize the differences and the
similarities, and accommodate both.
Bull, Landwehr, McDermott, and Choi [168] have drafted a taxonomy that classifies program security flaws according to the motive (intentional or inadvertent), the time of introduction (during development, maintenance, or operation), and place of introduction (software or hardware). They subdivide intentional flaws into malicious and nonmalicious, and -- continuing on to further substructure -- they provide examples for most of these classifications. However, some distinctions are not made. For example, there is no distinction between the existence of a flaw and its exploitation, where the former may be inadvertent and the latter intentional. Presumably, such problems will be addressed in any subsequent versions of their work.
There seem to be serious problems with trying to partition cases into malicious and nonmalicious intents, because of considerable commonalities in the real causes and considerable overlap among the consequences. Also, problems arise in trying to distinguish among human-induced effects and system misbehavior.
It is a slippery slope to attempt to define security problems in terms
of misuses of authority. For example, the Internet Worm was able to execute without any
explicit misuses of authority. In reality, no authority was exceeded in the
execution of the finger daemon, the use of the .rhost files, the sendmail
debug option, or the copying of an unprotected encrypted password file!
Similarly, many of the denial-of-service attacks do not need any authority.
Personal-computer viruses may attack in a variety of ways, including corruption of the boot sector, hard-disk partition tables, or main memory. They may alter or lock up files, crash the system, and cause delays and other denials of service. These PC viruses take advantage of the fact that there is no significant security or system integrity in the system software. In practice, personal-computer virus infection is frequently caused by contaminated diagnostic programs.
The number of distinct personal-computer virus strains grew from five at the
beginning of 1988 to more than a thousand early in 1992, and has continued
to grow steadily since then. By 1998 numbers exceeding 10,000 were commonly
quoted. The number is now much larger, and still growing at an alarming pace.
Many different types of PC viruses and variant forms exist. The growth in
the virus `industry' is enormous. In addition, we are beginning to observe
stealth viruses that can conceal their existence in a variety of ways and
distribute themselves. Particularly dangerous is the emergence of
polymorphic viruses, which can mutate over time and become increasingly
difficult to detect. Ultimately, the antiviral tools are limited by their
inherent incompleteness and by the ridiculously simplistic attitude toward
security found in personal-computer operating systems. Serious efforts to
develop survivable systems would do well to avoid today's personal-computer
operating systems, although the hardware is not intrinsically bad.
In addition to the attack methods noted above, several others are worth discussing here in greater detail, namely, the techniques numbered 1 through 14, and 23 in Table 2.
As demonstrated by the distributed denial-of-service attacks in February 2000, although such attacks can be carried out without any actual authorized access to the systems (hosts and network nodes) under attack, much more devastating attacks can be launched given the ability to penetrate. As a consequence, denials of service are at the same time very easy to perpetrate and very difficult to protect against.
The remaining forms of attack listed in Table 2 are somewhat more obscure than those noted above. The penultimate case involves misuse through inaction, in which a user, operator, administrator, maintenance person, or perhaps surrogate fails to take an action, either intentionally or accidentally. Such cases may logically be considered as degenerate cases of misuse, but are listed separately because they may have quite different origins.
The final case in Table 2 involves system use as an indirect
aid in carrying out subsequent actions. Familiar examples include
performing a dictionary attack on an encrypted password
file, attempting to identify dictionary
words used as passwords, and possibly using a separate machine to make
detection of this activity harder ([223]); factoring of very
large numbers, attempting to break a public-key encryption mechanism such as
the Rivest-Shamir-Adleman
(RSA) algorithm that depends
upon a product of two large primes being difficult to factor; and scanning
successive phone numbers, attempting to identify modems that might be
attacked subsequently.
Table 3: Illustrative Reliability Threats
Outside-environmental threats Environmental problems (earthquakes, floods, etc.) Power utility disturbances Electromagnetic and other external interference Inappropriate user behavior, unavailability of key persons National-infrastructure threats Glitches in telecommunications, air-traffic control, power distribution, and other infrastructures dependent on computer-communication infrastructures Middleware and application service threats Windows environments: cache management, crashes Browser and Web server flaws Accidentally corrupted code Database-specific threats DBMS software flaws Internal database synchronization and cache management Distributed database consistency Improper DBMS software upgrades and maintenance Improper database entries and updates Network threats Faulty network components (hosts, routers, firewalls, etc.) Distributed system synchronization Traffic blockage and congestion Operating-system threats OS software design and implementation flaws Improper OS configuration Improper OS upgrades and maintenance Failures of backup and retrieval mechanisms Software-development problems Faulty system design and implementation Poor use of software engineering techniques Bad programming practice Programming-language threats Compiler language inadequacies Compiler design and implementation flaws Hardware threats Flaws in hardware design and implementation Undesirable internal hardware state alterations Improper hardware maintenance Inside-environmental threats Internal power disturbances Self-generated or other internal interference
Threats to system and network reliability can take many forms. They can arise during requirements definition, system specification, implementation, operation, and maintenance. They can originate from hardware malfunctions, operating-system software flaws, network software flaws, application software problems, operational errors (e.g., in system configuration, management, and maintenance), environmental anomalies, and -- not to be ignored -- human mistakes. Some illustrative types of reliability threats are summarized in Table 3.
Essentially every one of the types of threats summarized can represent a fundamental threat to overall survivability. Environmental threats can be particularly devastating, especially if equipment and media are seriously damaged. Losses of power and telecommunications are especially critical, particularly if they last for long periods of time and if alternatives are not readily available. Threats to software and hardware reliability can have pervasive effects, although in some cases they may be surmounted.
System and network performance can be threatened as a result of many of the threats to reliability and security discussed in Sections 2.2 and 2.1, respectively. In addition to those threats, performance threats exist that do not directly stem from reliability or security. Inadvertent saturation of resources is one major class, perhaps because of runaway programs or inadequate garbage collection. Table 4 notes some of the concepts on which performance may depend.
Threats to survivability and its subtended requirements exist pervasively throughout all system application areas; throughout the layers of abstraction related to hardware, software, and people (as discussed in Section 3.3 and elsewhere in this report); and throughout the stages of development and use noted in Section 1.5. In particular, threats are pervasive throughout the services provided by the critical national infrastructures as well as computer-communication infrastructures. These threats provide the motivation for the survivability requirements discussed in Chapter 3.
Many threats to survivability exist that transcend system development and operation. Once particularly nasty example results from legislation that is beginning to work its way through U.S. state legislatures, namely, the Uniform Computer Information Transactions Act (UCITA). [359] As of June 2000, UCITA has already passed in Virginia and Maryland. UCITA encourages trapdoors that can enable a software developer to disable widely distributed software on demand; such a mechanism might easily be exploitable by outsiders as well as the developers. Besides, the distinction between insiders and outsiders is not clear-cut, as we have already noted. UCITA also permits developers to absolve themselves from liability, discourages source-available software, allows developers to forbid interoperability with proprietary interfaces, legalizes currently outlawed abusive practices, stifles competition, and is generally antithetical to the development of secure survivable systems. (The U.S. 1998 Digital Millennium Copyright Act is also problematical.)
To give a detailed example of the breadth of threats in just one critical-infrastructure sector, consider the safety-related issues in the national airspace, and the subtended issues of security and reliability. (See for example, Neumann's position statement for the International Conference on Aviation Safety and Security in the 21st Century [253].) Alexander D. Blumenstiel at the Department of Transportation in Cambridge, Massachusetts, has conducted a remarkable set of studies [46, 48, 47, 58, 49, 50, 51, 57, 53, 54, 55, 59, 56] over the past 14 years. In his series of reports, Blumenstiel has analyzed many issues related to system survivability in the national airspace, with special emphasis on computer-communication security and reliability.
Blumenstiel's early reports (1985-1986) considered the susceptibility of the Advanced Automation System to electronic attack and the electronic security of NAS Plan and other FAA ADP systems. Subsequent reports have continued this study, addressing accreditation (1990, 1991, 1992), certification (1992), air-to-ground communications (1993), air-traffic-control security (1993), and communications, navigation, and surveillance (1994), for example. To our knowledge, this is the most comprehensive set of threat analyses outside of the military establishment,12 and the breadth and depth of the work deserves careful emulation in other sectors.
To be more specific, Blumenstiel's early reports included a 1986 assessment [58] of vulnerabilities of the Advanced Automation System (AAS) to computer attacks. The AAS was planned at the time as the next-generation system of air-traffic-control computers and controller displays for installation in all air-traffic-control centers. Blumenstiel's study found vulnerabilities to a range of computer attacks in this system and recommended countermeasures. (In 1999, the FAA is finally beginning to upgrade the displays, replacing technology from the mid-1960s.) The FAA specified the countermeasures as a requirement for this system. Blumenstiel also assessed vulnerabilities of the FAA's National Airspace System Data Interchange Network (NADIN), a packet-switched network for interfacility communication of air-traffic-control data [57]. Based on this assessment, Blumenstiel prepared a security management plan for NADIN that has been implemented in the system to protect critical data transmissions. Another study assessed vulnerabilities of the Voice Switching and Control System (VSCS). The VSCS is a computer that controls the switching of air-traffic-control communications (between controllers and flight crews and between controllers on the ground) at all air-traffic-control centers. Another study [51] identified and assessed risks to air traffic from electronic attacks on the entire National Air Space System, including air-traffic-control computers, radars, switching systems, and automated maintenance information. This study prioritized all the systems in terms of vulnerabilities and the potential impact of successful attacks on air traffic, including the potential for crashes and the cost of potential delays, and estimated the overall risk. Blumenstiel also produced the security plans for FAA systems required by Public Law 100-235, authored FAA's requirements for computer security accreditation (and designed and developed software to automate the accreditation reporting process) and sensitive application certification [53, 54, 55]. He authored the NIST Guidelines [52] on FAA AIS security accreditation. He was the principal author of the June 1993 Report to Congress on Air Traffic Control Data and Communications Vulnerabilities and Security [59]. Additional studies under Blumenstiel's direction involved assessments of air-traffic-control telecommunications systems to electronic attacks, and development of the strategic plan to protect such systems.
With respect to the national airspace, and with respect to the other national infrastructures and the computer-communication infrastructures, it is clear that the threats are pervasive, encompassing both intentional and accidental causes. However, it is certainly unpopular to discuss these threats openly, and thus they tend to be largely downplayed -- if not almost completely ignored.
In general, it is very difficult for an organization to expend resources on events that have not happened or that are perceived to be very unlikely to occur. The importance of realistic threat and risk analyses is that it becomes much easier to justify the effort and expenditures if a clear demonstration of the risks can be made.
Things derive their being and nature by mutual dependence and are nothing in themselves.
Nagarjuna, second-century Buddhist philosopher
We next elaborate on the requirements, threats, risks, and recommendations outlined in [29] and discussed in Chapter 1 of this report, in such a way that those requirements could apply broadly to a wide range of survivable system developments and to the procurement of systems with critical requirements for survivability.
Our approach is rooted in the establishment of a sound basic set of generic requirements for survivability and the explicit determination of how survivability in turn requires other secondary properties. Secondary properties include various aspects of security in preventing willful misuse; reliability, fault tolerance, and resource availability despite accidental failures (with real-time availability when required); certain aspects of functional correctness; ease of use; reconfigurability under duress; and some sense of overall system robustness when faults exceed tolerability. In turn, security requirements include integrity of systems and networking, confidentiality to avoid dissemination of information that could be useful to attackers (especially cryptographic keys and authentication parameters), high availability and prevention of denials of service despite malicious actions, authorization, accountability, rapid detectability of adverse situations, and prevention of other forms of misuse. Reliability requirements include fault tolerance, fault detection and recovery, and responses to unexpected failure modes. Security and reliability have some requirements that are related, such as resistance to electromagnetic and other interference. Furthermore, some of the requirements interact with other requirements, and must be harmonized to ensure that they are not contradictory. Each requirement has manifestations at each layer of abstraction, and corresponding special issues that must be accommodated. Particular layers of abstraction must address relevant properties -- of applications, databases, systems, subsystems, and networking software. Types of adversities to be covered by the requirements must include the full spectrum of applicable potential threats, such as malicious software and hardware attacks, system malfunctions, and electronic interference noted above. All reasonable risks must be anticipated and protected against. Thus, our approach is developing a somewhat canonical requirements framework for survivability that encompasses all the relevant issues, and that demonstrates how the different requirements interrelate.
Of particular importance are the ways in which some of these requirements interact with one another, and how when systems are developed to satisfy those requirements, the components supposedly addressing different requirements actually interact with one another. Ideally, it is helpful if those interactions are understood ahead of time rather than manifesting themselves much later in the development process, or in system use, as seemingly obscure vulnerabilities, flaws, risks, and in some cases catastrophes.
For any given application, the specific requirements must be derived from knowledge of the operational environment, the perceived threats, the evaluated risks, many other practical matters such as the expected difficulty and costs necessary to implement those requirements, the available resources in funding and manpower, and considerations of how the peculiarities of the given application are likely to compound the difficulties in development. Mapping the generic requirements onto the detailed specific requirements then remains a vital challenge that must be undertaken before any serious development effort is begun.
Neumann gave a keynote talk in June 2000 on the role of requirements
engineering in developing critical systems, for the 2000 IEEE International
Conference on Requirements Engineering, The visual materials are on-line
http://www.csl.sri.com/neumann/icre00talk+4.ps.
In defining survivability and some of the requirements on which it most depends -- security, reliability, and performance -- we work primarily from the perspective of requirements that can be dependably enforced and applied to enhance the overall system and network survivability.
Survivability [An overarching requirement: /|\ a collection of / | \ emergent properties] / | \ / | \ / | \ / | \ / | \ / | \ / | \ / | \ / | \ Security Reliability Performance [Major subrequirements] /|\ /|\ /|\ / | \ / | \ / | \ / | \ / | \ / | \ / | \ / | \ / | \ [Subtended Inte- Conf- Avail FT Fail RT NRT Avail requirements: grity id'ity * |\ modes /\ /|\ * FT=fault tolerance /| |\ |\ | \ /| \/ /|\ RT=real-time / | | \ | \ | \ / | Prior- / | \ NRT=non-real-time] / # | \ | \ # ities / MLI No MLS Dis- MLA \ No / [More detailed / change | cret- | \ change / requirements] / /| | ion- | \ / / / | | ary | * Unified * / / | | | | availability X Sys Data X X requirements /| |\ [X = Shared components of MLX!!] / | | \ [* = Reconvergence of availability] / | | \ [# = Reconvergence of data integrity]Figure 2: Illustrative Subset of Requirements Hierarchy
As observed at the beginning of this chapter, numerous properties are necessary for overall survivability, some of which are -- or in some cases merely seem to be -- interdependent. A highly oversimplified but nonetheless illustrative summary of a portion of the subtended requirements hierarchy is given in Figure 2.13 We have somewhat arbitrarily taken security, reliability, and performance as three major requirements that can contribute in rather basic ways to achieving high-level survivability requirements. (Other conceptual arrangements of the hierarchy are also possible. In addition, it is worth noting that the overarching requirement for human safety is evidently at an even higher level than survivability, because human safety typically depends on overall system survivability and other mission-critical properties.)
In Section 1.2.2 we observe that there are multiple but closely related manifestations of availability. This is depicted graphically in Figure 2 by a common node ("Avail") subtended from both security and reliability, and by a comparable node subtended from performance. (Each node denoted by an asterisk denotes a reconvergence of a common set of requirements across the three major requirements.) Although it is usually desirable to keep these three manifestations of availability separate during a requirements specification and analysis, it is highly advantageous to consider them in an integrated way during system design and implementation. Thus, the specification of the requirements can benefit from an understanding of the ways in which the different manifestations interact with or depend on one another. Furthermore, techniques that contribute to more than one of the major requirements can be implemented more uniformly.
As noted at the beginning of Chapter 1, the term survivability denotes the ability of a computer-communication system-based application to continue satisfying certain critical requirements (e.g., requirements for security, reliability, real-time responsiveness, and correctness) in the face of adverse conditions. The scope of adversity may in some cases be precisely defined, but more typically it is not well defined.
Some of the adversities can be foreseen as likely to occur, with consequences that can be perceived as potentially harmful; these can be enumerated and defined. Other adversities may be foreseen as unlikely, or as not having serious consequences to worry about -- or may not even be anticipated at all. Ideally, appropriate survivability-preserving actions should be taken irrespective of whether the adversity was foreseen or not. Defensive system design and defensive programming practices are necessary to cover otherwise unanticipated events. Although there can clearly be circumstances in which system survival is not possible -- for example, when all communication lines and all power are out -- some reasonable contingency plans should be in place, even if in the last resort it is merely emergency actions by the operations staff. In addition, the blame in cases of complete outages may rest with insufficient foresight in system design.
Survivability in this sense can be defined only in terms of specific requirements that must be met under incompletely specified circumstances (where those circumstances may possibly be dynamically changing), which will often differ from one type of adversity to another.
Specific survivability requirements typically vary considerably from one application to another. For example, one set of system requirements might allow degraded performance or other real-time dynamic tradeoffs in times of extreme need (e.g., being able to relax certain security requirements in favor of maintaining real-time requirements when under attack).14 Another set might prioritize the computational tasks and permit degradation according to the established priorities. In general, a system's survivability requirements might specify that the system must withstand attacks (providing integrity and availability aspects of security) and be resistant to hardware malfunctions (providing reliability and hardware fault tolerance), software outages (providing resistance to hardware- or software-induced software crashes), and acts of God (e.g., anticipating the consequences of communications interference, floods, earthquakes, lightning strikes, and power failures) that might otherwise render the system completely or partially inoperative. In this context, survivability appears in the guise of a high-layer system integrity requirement.
Thus, we adopt the following tentative working definitions:
System survivability can be defined in terms of an overall application or specific services, or in terms of specific computer-communication systems, subsystems, or networks. Each type of potential adversity may have its own measure of survivability.
In the definitions above, the term "arbitrary adversities" implies more than merely the ability to withstand "known adversities" or "specified adversities" -- it also implies a characterization of the ability to withstand adversities that were not anticipated such as those that exceed the reliability and security tolerances supposedly covered by the design. In each case, a meaningful assessment of survivability rests not only on what happens when an anticipated adversity occurs, but also on what might happen in response to unanticipated events. This requires some determination of the actual coverage, not just the designed coverage with respect to anticipated faults and threats.
Continued enforcement of system integrity, system availability, data confidentiality, and data integrity (for example) are typically fundamental aspects of survivability. Whenever specific lower-layer survivability properties are explicitly included among their constituent system security properties, then survivability can also be considered as a security property (and, specifically, an integrity property). However, for present purposes we consider application service survivability as an overarching property to be maintained by the application in its entirety.
Intuitively, the natural-language meaning of security implies protection against undesirable events. System security and data security are two types of security. The three most commonly identified properties relating to security are confidentiality, integrity, and availability. There are also other important forms of security, such as the detection of misuse and the prevention of general misuse that does not necessarily violate confidentiality, integrity, or availability, particularly when committed by authorized users.
With respect to any particular functional layer, the primary attributes of security are summarized as follows:
Identification and authentication are essential to the enforcement of confidentiality, integrity, availability, and prevention of generalized misuse, as well as to meaningful misuse detection. They may be either explicitly designated as system security requirements or else subjugated to the implementation, but are fundamental in either case.
Mandatory policies for confidentiality (e.g., multilevel security), integrity, availability, and survivability (MLS, MLI, MLA, and MLX, as introduced in Section 1.2) have the advantage that they cannot be violated by user actions (assuming that the mechanisms are correctly implemented), but have the disadvantage that they may be inflexible for certain kinds of applications. On the other hand, that inflexibility is precisely what makes them powerful organizing architectural concepts.
Covert channels (out-of-band signaling paths) represent potential losses of confidentiality. They are a problem primarily in multilevel-secure systems, in which it may be possible to signal information through inference channels to lower levels, in violation of the security policy. However, covert channels are often not explicitly addressed by system security policies, and are typically not prevented by conventional security access controls: they bypass conventional controls altogether rather than violating them. Avoidance of covert channels is a problem that must be addressed during system design, implementation, and operation. Detection of covert channel exploitation is a problem that must be addressed during operation (see Proctor and Neumann [310]). Two types of covert channels are recognized: storage channels (which exploit the sharing of resources across multiple security levels using normal system functions in unusual ways), and timing channels (which exploit the time-sensitive behavior of a system, perhaps by observing the real-time behavior of a scheduler). Because most existing systems still have overtly exploitable security flaws, covert channels are often of less interest. However, in highly critical applications, they could be an important source of system compromise, for example, with the aid of a Trojan horse that is modulating the covert channel.15
A useful paper by Millen [210] summarizes 20 years of modeling and analysis of MLS covert channels. Covert channels can also exist with respect to MLI, MLA, and MLX, but they seem less easy to identify and exploit.
At each layer of abstraction, each of these concepts may have its own interpretation, in terms of the abstractions at that layer.
Threats to security are considered in Section 2.1.
Many requirements for reliability and fault tolerance are appropriate in addressing the various types of threats to reliability summarized in Section 2.2 and Table 3. Most of these reliability requirements can have major implications on system and network survivability, in hardware, system software, network software, and application software. In the absence of serious efforts at generalized dependence, the failure of a component may typically result in the failure of higher-layer components that depend on the failed component.
Some of the reliability concepts are closely tied together with security concepts. For example, reliably high availability with respect to systems and networks is closely related to the prevention of denials of service. Also, degraded performance modes are closely linked with fault tolerance and responses to detected anomalies.
In an early (D)ARPA study, 1972-1973 [261], we recommended that fault tolerance can most effectively be used at each hierarchical layer according to the particular needs of each of the specific abstractions at that layer. That approach is still valid today, and is embodied in the architectural directions pursued in this report. A recent article by Nitin Vaidya [378] further pursues a design principle of multilevel recovery schemes in which the most common cases are disposed of most quickly. (Vaidya considers only two levels, but the concept is readily generalized to more levels, or to a continuous spectrum.)
Numerous examples of survivability failures related to inadequate reliability and fault tolerance are given in Neumann's RISKS book [250], along with a summary of techniques for improving reliability and fault tolerance.
Complete system and network outages are an extreme form of performance degradation, whether caused accidentally or intentionally, through reliability problems or security problems. However, in some cases even relatively small performance degradations can cause unacceptable behavior, particularly in tightly constrained real-time systems. Thus, performance requirements must be closely coupled with those for security and reliability.
Performance depends on availability in both its security manifestations (e.g., prevention of denials of service) and its reliability manifestations (e.g., fault tolerance and alternative computation modes). This confluence of subrequirements is illustrated in Figure 2 as the reconvergence of what is otherwise depicted as a pure tree structure.
The reconvergent nodes indicated by an asterisk (*) in the figure could of course be split into separate but essentially identical nodes if the sanctity of the pure tree structure were important. However, it is not important -- and in fact illustrates an important point: apparently different subrequirements that originate from seemingly disjoint requirements are in fact best handled by a common integrated mechanism, rather than treated completely separately. For implementing assured availability, it is true that different techniques may indeed be useful for (1) preventing malicious denials of service, (2) preventing accidental denials of service, (3) preventing failures due to faults that exceed the coverage of fault tolerance, (4) ensuring adequate performance despite intentional acts, (5) ensuring adequate performance despite unintentional acts and system malfunctions, and (6) ensuring adequate performance despite acts of God. On the other hand, by taking a systematic view of these supposedly different aspects of availability, it is likely that many common mechanisms can work synergistically.
Many other interdependencies also exist. For example, the aspect of integrity relating to prevention of undesired changes (to data, programs, firmware, hardware, communications media, and so on) is fundamental to security, reliability, performance, and of course survivability in the large. Several manifestations of the no-unintended-change requirement are indicated by a sharp (#) (the erstwhile octothorpe in early telephony) in the figure, and discussed further in Section 5.12. Similarly, the confidentiality of sensitive information such as cryptographic keys can undermine many desired system properties.
Dependencies in requirements are sometimes not recognized until well into design and implementation. For example, extensive requirements for reliability and availability may induce additional risks with respect to security and survivability, such as those that result from replication of common mechanisms that introduce multiple common vulnerabilities, or the use of different mechanisms that introduce different vulnerabilities. Similarly, extensive security mechanisms may have deleterious effects on performance and system usability. To avoid performance degradation, security controls are often disabled.
As noted, enterprise survivability is a requirement on the enterprise as a whole. Other such highest-layer application requirements might include preservation of human safety for friendly humans, destruction of unfriendly humans by a tactical system in a hostile environment, and detailed accountability of system and human actions in terms of the application functionality.
System survivability typically depends on two types of properties, sometimes called liveness properties (implying availability) and functional safety properties (implying functional correctness). Alpern and Schneider [8] have shown that every property can be expressed as a combination of functional safety properties and liveness properties, relative to definitions that have evolved from Lamport [162]. Intuitively, functional safety properties imply that nothing bad happens, while liveness implies that eventually something good happens. Indeed, most application-layer requirements (e.g., survivability and human safety) and system-layer requirements have components of each type.
We do not need to make a precise distinction here between the two types of properties. However, we do recognize that some of the desired properties have time-dependent aspects -- particularly in highly distributed systems.
Failure of the system or subsystem to enforce any of a variety of properties can result in a loss of application survivability. Some of those necessary underlying properties on which application survivability may depend are illustrated next. In each case, the term system can equally well imply an entire computer-communication system or a subsystem thereof.
Some of the necessary properties are largely time independent, although some
of them have certain time-dependent attributes. We consider the general
properties first and then reconsider those with specific real-time
attributes. For simplicity, we include networking and communications issues
as an integral part of the system issues, particularly in distributed
systems.
Necessary system security properties:
Necessary network security properties:
Although the foregoing system and network security issues all imply attempts to
constrain usage by users, operators, system programmers, and administrators,
they inevitably depend to some extent on compliant system use by those
people. Misuse by apparently authorized individuals is a serious potential
problem in many applications.
Necessary system and network reliability properties:
It is useful to note that the security and reliability properties have some
time-dependent attributes, such as the following.
Necessary time-dependent security properties:
Necessary time-dependent reliability properties:
Necessary performance properties:
Necessary operational properties:
One of the major challenges of system development and operation is to understand a priori all the relevant requirements, as well as their implications on lower system layers (including hardware and communications), and to organize the system development accordingly.
Further issues on which survivability depends include human behavior -- on the part of system designers and implementors, operators, users, and maintainers, for example -- and acts of God. However, these may be anticipated to a considerable extent by suitable system design and operation with respect to security, reliability, and performance considerations.
In any particular application, certain vulnerabilities may not exist, or some of the threats that could expose those vulnerabilities may not exist, or the risks may be deemed inconsequential. In such cases, the survivability problem may be simplified somewhat. In general, however, it is very dangerous to base simplifications in system design, implementation, or operation on assumptions that may not be valid in practice. Therefore, great care must be taken to provide adequate assurance in any efforts that are permitted to ignore one or more of the foregoing necessary properties.
Functional Security Reliability Performance layer concepts concepts concepts Users, Human integrity, Human reliability, Human responsiveness, operators, education, training, education, training, ease of use, admins, ... user identity human interfaces education, training Application Application Functional correctness, Service availability, software integrity and redundancy, real-time performance, (SW) confidentiality robustness, recovery functional timeliness Middleware SW integrity and Functional correctness, Functional timeliness (MW: DBMS, confidentiality redundancy, DB backup, of Web, remote DBs, DCE, CORBA in DCE, Webware, robustness, recovery and file servers Webware) DB access controls Networking Netware integrity, Netware integrity, Netware throughput and (Netware) confidentiality, error correction and guaranteed service, availability, fault tolerance alternative routing and node nontamperability, in transmission and other infrastructural peer authentication, routing, especially factors, especially especially wireless in wireless roving bandwidth Operating OS integrity, OS integrity, OS integrity, system data confidentiality, fault tolerance, guaranteed service, (OS) guaranteed service, sound asynchrony, avoidance of deadlocks, OS nontamperability, archiving/backup performance optimization, OS development and OS development and OS development and maintenance, OS maintenance maintenance user authentication Hardware Access controls, HW fault tolerance, Processor/memory speed, (HW) protection domains, instruction retry, communication bandwidths, HW nontamperability, error-correcting codes, contention control, configuration control, HW correctness, adequate HW configuration, protection against protection against protection against intentional interference, accidental interference, any interference, HW development HW development HW development Table 4: Some Survivability Attributes at Different Logical Layers
Survivability is meaningful primarily as an emergent property of an entire computer and communication system complex, or, more broadly, of a collection of computer-based applications. Survivability also transcends lower-layer policies relating to subsystem reliability, integrity, and the like. Certain aspects of survivability are meaningful with respect to hardware as well.
Some of the properties on which application survivability typically depends are illustrated in Table 4, under the approximate headings of security, reliability, and performance. These three headings partially overlap, even among the different manifestations at each functional layer. For example, system integrity at any particular layer clearly contributes to security, reliability, and performance at higher layers. Similarly, prevention of malicious and accidental service denials at any layer clearly contributes to security, reliability, and performance at higher layers.
Human safety is very similar in its dependence on the same properties of the lower-layer functionality. Human safety is also largely an emergent property of the entire system complex, although particular aspects of safety can be considered at lower layers of abstraction. (For example, see [173, 175].)
Clearly, there are many more detailed properties of lower layers on which the system properties in turn depend. These are not shown explicitly, for reasons of descriptive simplicity.
Before attempting to carry out an architecture and its implementation, a vital preliminary step is to map the overall mission requirements into a specific subset of the generic requirements for survivability and its subtended attributes. This is at present a human endeavor, although the existence of computer-aided analysis tools can be contemplated to assist in requirements analysis, and subsequently to assist in determining the sufficiency of the architecture with respect to the chosen requirements.
The mapping process should take into account expected vulnerabilities, threats, and risks. It should anticipate the needs of the full range of expected applications and capabilities. The needs for each of the following functional capabilities should be anticipated from the outset, rather than discovered later in the development, and specific requirements defined.
Many deficiencies in existing subsystems, systems, and networks seriously hinder the attainment of survivability. We identify those that are fundamental, and recommend specific approaches to overcome those inadequacies.
In this context, survivability is considered in the broadest possible sense, encompassing measures to handle all realistic threats -- including, for example, hardware malfunctions, software flaws, accidental and malicious misuse, electromagnetic interference, acts of God, and other occurrences that are typically unanticipated. We seek to provide a realistic architectural bridge across the gap that exists between (on one hand) the present status quo of inherently incomplete requirements, criteria, standards, protocols, components, and systems, and (on the other hand) the need for survivable systems and networks that can be rapidly configured out of off-the-shelf commercial products, specifically tailored to particular applications. Unfortunately, many systems that exist today or are foreseen for the near-term future are likely to be inadequate for these purposes.
This chapter identifies some of these shortcomings, including technological deficiencies (Sections 4.1 and 4.2) and other problems (Section 4.3). Chapter 5 presents recommendations for overcoming those limitations. Chapter 7 continues the identification and analysis of the deficiencies in the context of survivable architectures, and presents specific recommendations for alternative system and network architectures, new system components, fundamental changes in how systems are developed, and guidelines for implementation.
With the almost total dependence of the U.S. Government, critical infrastructures, and the public sector on commercially available off-the-shelf systems, subsystems, and networks, all survivability-critical applications are seriously at risk.
Schneier and Mudge [350]16 have uncovered an astounding variety of elemental flaws in Microsoft's implementation of the Point-to-Point Tunneling Protocol (PPTP), only a few of which have apparently been fixed.
On a much broader front, Schneier [348] examines many of the characteristic flaws that result from improperly embedded cryptography.
The previous section outlines numerous deficiencies in computer systems and in networking software. However, some fundamental problems transcend deficiencies in systems and networking software -- specifically, those relating to the underlying information infrastructure. We are becoming critically dependent on the Internet, and are likely to be even more dependent on whatever succeeds it.
Unfortunately, the Internet has become an enormous self-perpetuating organism of its own -- with no coherent management, no overall control, and almost no ownership by any national or corporate entities (except in nondemocratic countries). Its existence is almost totally unregulated, and it is run on the fly in a strikingly unprofessional way. Because traffic may be routed arbitrarily through potentially untrustworthy and unreliable nodes, retrying over alternate routes is at present typically the best that can be done when problems are experienced. But that approach is vulnerable to massive denial-of-service attacks. If a vital gateway is down, an entire enterprise may be off the Internet. In general, weaknesses in the infrastructure become weaknesses in the computer systems and networking software. For example, the fundamental deficiencies in networking protocols noted in Section 4.1 affect not just local networks and enterprise-internal networks, but also the Internet; they are likely to haunt any future information infrastructures unless radically superseded. Conversely, weaknesses in computer systems and networking software can result in weaknesses in the information infrastructure -- affecting telecommunications and power distribution as well.
System developments fail for a wide variety of reasons, including inadequately specified requirements, inadequately specified system designs, poor implementations, poor documentation, poor management, and poor choices of programmers. Projects that have many programmers seem to be much less likely to succeed, although extremely gifted management and skilled team-oriented programmers can make such efforts successful. (However, there are very few success stories.) Projects with inadequate staffing or misassigned personnel can also be seriously impaired. Overcommitted contractors and improperly guided subcontractors are also sources of development risks.
Although entire books can be and have been written about these deficiencies and the resulting risks (e.g., [64, 250]), the emphasis here is on overcoming the deficiencies -- as addressed in the next chapter.
We can't solve problems by using the same kind of thinking we used when we created them.
Albert Einstein
Given the deficiencies identified in Chapter 4, we next consider what might be done to overcome them. Various approaches toward prevention, detection, reaction, and iteration are summarized in Table 5 for each of the three primary attributes of survivability noted in Figure 2 and discussed further in this and subsequent chapters. Specific architectural recommendations are considered in Chapter 7 for systems and networks with stringent survivability requirements. Ultimately, the use of robust architectures is absolutely fundamental to the recommendations of this report.
Approach Relability Security Performance Prevention Robust architecture: Robust architecture: Robust architecture: Redundancy: Domain isolation, Spare capacity error correction, access controls, fault tolerance authorization, tolerance Detection Redundancy: Integrity checks, Performance monitoring error detection anomaly/misuse detection Reaction Forward/backward, Security preserving Reconfiguration recovery reconfiguration, tolerance Iteration Fault removal Exploratory Redesign, off-line patches tradeoffs Table 5: Defensive Measures
Perhaps the most important step toward attaining system and network architectures that are capable of meeting advanced survivability requirements is to have a well-defined set of detailed requirements. However, for those requirements to be sensibly matched to the realistic needs, it is important that there be a well-defined and well-understood model of the mission that a specific system is intended to fulfill. In the absence of such a model, it is difficult to assess the adequacy of a given architecture, the dependence on external infrastructures and substructures, and the consequences of systemic breakdowns or attacks on the system.
Two types of models would be useful -- generic model frameworks that can be tailored to specific needs, and specific models applicable to particular systems.
Two fundamentally different architectural approaches seem possible -- either increase the security, reliability, and survivability of the most critical components, or else develop system and network architectures that are survivable despite the presence of inherently weak components. In practice, a combination of both approaches is desirable, for several reasons:
Indeed, component survivability can benefit greatly from component diversity, particularly in the context of architectures that are designed for robustness. In such an architecture, it becomes essential to identify the most critical components, and to concentrate sufficient architectural strengths in those components. The basic challenge is to considerably reduce the extent to which all subsystems must be extensively trustworthy. Identifying the critical components and minimizing the dependence on untrustworthy components are both extremely difficult, and are pursued in this report. As noted in Section 5.1, having a well-defined mission model and detailed requirements is a vital precursor.
System architectures must address the necessary survivability-relevant requirements, including reliability, fault tolerance, and security -- irrespective of which components are actually trustworthy with respect to which requirements. In addition, these architectures must be flexible enough to support real-time applications and supercomputing requirements, rather than necessitating special-purpose designs. Various architectural alternatives are considered in Chapter 7. An alternative that approaches multilevel survivability (Section 1.2.8) might lead to a sensible system structure that is of interest even in non-MLS systems and networks. However, MLS should be taken not as an attempted universal property of kernels and trusted computing bases (as was attempted with MLS), but rather as a potentially useful architectural driving force in the context of the notion of generalized dependence.
Perhaps the most fundamental architectural concept involves the isolation of potentially bad activities from whatever functionality must be trustworthy. This is considered in Chapter 7.
Section 4.1 notes that existing network protocols leave something to be desired with respect to network survivability. However, there is an amazing amount of energy and effort going into protocol development. For background on TCP/IP and related protocols, see the massive collection of Internet draft proposals and subsequently Requests for Comments (RFCs), which collectively represent a goldmine of information on emerging Internet protocols.
In the interest of dramatically increasing overall network robustness, two new Internet Engineering Task Force (IETF) draft Internet protocols are of particular interest here:
Among the existing RFCs, several recent ones are worth noting:
This provides security services for the IPO layer in IP versions 4 and 6.
Of particular importance is the need for robust public-key infrastructures (PKIs) that compatibly provide public-key certificates and validation of the genuineness of the certificate authorities and verification authorities, with sufficiently good performance, to make cryptographically protected interoperability practical. Many commercial distributed PKIs are emerging, and are expected to win out over a few highly unified PKIs. However, compatibility and interoperability are still badly lagging. Certificate authorities are by themselves inherently limited (for example, by issues of trustworthiness). Validation authorities are necessary. In essence, a certificate authority can be issued off-line as needed. A validation authority is invoked on-line per transaction, and can provide stronger revocation, as in the Valicert approach of certificate revocation trees (see http://www.valicert.com).
Existing cryptographic algorithms (especially the AES algorithms) appear to be adequate for the foreseeable future needs. However, we urgently need better cryptographic protocols and greater dependability in their implementations. Flaws have been discovered in various popular protocols (for example, Needham-Schroeder). See a recent report by Abadi and Gordon [2] as part of a series of papers on formalizing cryptographic protocols (they include copious references to earlier work), along with further discussion in Section 5.9.
Composability of components such as protocol implementations is considered in Section 5.8. However, composability by itself is not enough. Knowing that vulnerabilities abound, a particular concern is that by concentrating trustworthiness around one functionality such as a public-key infrastructure makes that functionality an attractive subject for attack. Even if the mechanisms themselves have adequate integrity and nonspoofability (which is unlikely), they become easy targets for denial-of-service attacks.
Roving end-user terminals with wireless communications represent huge challenges for networking. Strong noncompromisible end-to-end cryptography is essential; link encryption may also be important, particularly in warding off denial-of-service attacks on the network nodes.
The DARPA Global Mobile effort -- GloMo
(http://www.darpa.mil/ito/research/glomo/index.html) -- is seeking
to address some of the basic engineering issues in research and prototype
developments, and is also attempting to use Fortezza technology for
cryptographic approaches to retrofitting security into the GloMo research
environment
(http://www.glomo.sri.comhttp://www.glomo.sri.com/).
However, achieving secure
portable computer communications is a very difficult task, and at present
security and to a large extent survivability are not driving requirements in
most of the ongoing DARPA GloMo research programs; rather, security (not to
mention survivability) seems to be thought of as something that can be added
later -- which goes against the teachings of years of experience in system
development.
The components that are most critical for survivability -- and therefore deserving of the most defensive design, development, and maintenance attention -- are typically authentication servers, file servers, network servers, boundary controllers (including access control mechanisms, firewalls, guards), as well as other components that must necessarily be at least partially trusted. From a reliability point of view, file servers and network servers are particularly critical. From a security point of view, authentication servers, boundary controllers, and cryptographic units must receive extra protection. From a system integrity point of view, cryptographically generated integrity seals and proof-carrying code are useful techniques to hinder undetected system modifications.
Several considerations are necessary to be able to readily configure survivable systems and networks out of subsystems. Architecturally, the subsystems must have appropriate functionality. They must also be compatible with one another, and their interfaces must be easily composable. System and network management facilities are also critical to the maintenance of survivability. In particular, the configuration management system must be both comprehensive and comprehensible enough to permit consistent administrative control.
Given the nature of the threats and natural failures, it is essential that systems and networks be capable of dynamic reconfiguration, with or without human intervention according to the real-time requirements. This implies that requirements and dynamic policies must address the needs for reconfiguration that maintains whatever functionality must be retained, with appropriate security and reliability. Each potential change carries with it certain implications, such as whether the resulting system configuration will be less survivable or more survivable, and whether it will be easier or more difficult to attack. Anticipating the consequences of each possible reconfiguration is extremely difficult, but should be a part of any mission-critical architecture. Thus, there are design-time tactical and strategic issues that must foresee the run-time tactical and strategic issues. Such considerations will be particularly important whenever information warfare is a vital concern.
The previous sections of this chapter outline improvements that need to be made in computer systems and in networking software. However, Section 4.2 notes that some fundamental problems cannot be solved through better systems and networking software -- specifically, those relating to the underlying information infrastructure (such as the Internet as it exists today). Overcoming the limitations of the Internet is an enormous undertaking, but some drastic measures must be taken immediately to prevent those limitations from becoming significantly worse. The biggest problem of course is that the Internet is an international entity. In May 1996, at a hearing of the U.S. Senate Permanent Subcommittee on Investigations (Senate Committee on Governmental Affairs), in light of testimony on difficulties that exist with being connected to the Internet, Senator Sam Nunn ([377], pages 10-11) asked in essence what would happen if we (the United States) simply cut ourselves off from the rest of the Internet. Perhaps having a national computer-communication infrastructure in addition to the international Internet is in fact a good idea, although it would not solve the problem that the computer systems and networking software are not secure enough, and would defeat the global information interchange purposes of the Internet. But even more fundamentally, if it had gateways and dial-up connections that could be accessible from the rest of the world, it would be very difficult to seal it off. Nevertheless, rigidly controlled private networks are clearly a good idea. (See also [252, 254, 226] for subsequent relevant Senate testimonies.)
This leads us to one of our most far-reaching conclusions on overcoming the existing deficiencies. It is urgently necessary to supplant the existing TCP/IP/ftp/telnet/udp/smtp set of protocols. Ideally, a fundamentally new set of protocols could be engineered to provide the necessary survivability, security, reliability, and performance (all at once), with robust authentication as a fundamental requirement. Alternatively, a few of the existing protocols might be successfully modified, but we are not encouraged at this point at the likelihood of small incremental improvements. Although IPSEC and IP Version 6 attempt to overcome some of the most glaring weaknesses, they are still not strong enough. In certain less critical cases, it might be possible to use a subset approach, parameterizing the protocols accordingly. However, in the long run, the strategy of replacing the existing fundamentally defective protocols with a new set of survivable and secure protocols might actually be less costly than trying to coexist with those protocols that are clearly not up to the job. In that way, it would be possible to develop highly survivable separate information structures, with perhaps some possibility of trustworthy but highly controlled interoperability with the rest of the world (e.g., the Internet).
In general, system development practice is truly abysmal and must be improved dramatically. If systems are to be configured primarily out of off-the-shelf components, then development practice is vital to the dependability of those components. However, it is not realistic to expect that operating systems and networking software will improve dramatically. On the other hand, once subsystems have been developed, it is too late to quibble about bad development practice -- particularly if completed systems and networks are to be assembled rather than developed. Furthermore, the best development practice is not very effective if the basic architecture is not suitable.
A recent thoughtful but somewhat simplistic article by Paul Green [119] is worth noting, entitled "The art of creating reliable software-based systems using off-the-shelf software components." Although the article is concerned primarily with application-system reliability, it presents a few practical guidelines based on Green's 17-year experience at Stratus Computer. For example, if you are a procuring agent, he suggests (we oversimplify for descriptive purposes) that you should select vendors who are committed to reliability, insist on good software engineering practice throughout, make sure your contracts cover the entire life cycle, test in the large and force that process on your contractors, and don't pay off vendors until they deliver what they are required to produce (assuming that you have specified the requirements adequately in the first place).
Good software engineering practice involves the use of modular design, functional abstraction, well-specified functionality, reusable and interoperable interfaces, information hiding to mask implementation detail, and the use of analysis techniques and tools that greatly reduce the likelihood of flaws and programming errors. Good software engineering practice therefore should also involve the use of high-level programming languages that are intrinsically less susceptible to characteristic errors -- such as missing bounds checks, mismatched types and mismatched pointers, off-by-one errors, and missing exception conditions. As widely used as the C programming language is, it is a continual source of programming errors by skilled programmers as well as novices. Careful documentation is also essential. Potentially, the most powerful techniques may in the long run involve formal methods (Section 5.9), but those techniques are labor intensive and are now becoming much more effective in practice.
Commercial techniques for software engineering tend to emphasize procedures for controlling and constraining the processes involved in the software development cycle: requirements engineering, specification, implementation, testing, management, quality assurance, and risk management. Testing is inherently incomplete, with the old adage that it demonstrates only the presence of bugs rather than the absence of bugs. Metrics are popular for the development process and for assessing code quality, but are not definitive. Code inspections are also popular, but not conclusive. Assessment of risk management is inherently a risky process (see [250], pages 255-257).
Many of the commercial software engineering techniques are supported by automated or semiautomated tools. Indeed, the ones that are not supported by mechanical tools are of very limited value. The use of software engineering tools can be advantageous, particularly in detecting the characteristic errors noted above. One of the most useful tools in recent years is the purify program, which detects garbage collection problems resulting from unfreed storage. However, overreliance on such tools can result in serious risks in the absence of human intelligence. Furthermore, overemphasis on the processes rather than on the requirements, the designs, and the implementations themselves can be misleading. Not surprisingly, the Year-2000 Problem is forcing a rethinking of much of the old-style conventional wisdom relating to software engineering. Those who take the challenge seriously are likely to realize the need for radical change in making the so-called software engineering field more of an engineering discipline. (See a provocative article by David Parnas [283] on that subject.)
Use of the object-oriented paradigm in the system design itself may be beneficial (particularly with respect to system integrity), for example, creating a layered system in which each layer can be looked upon as a strongly typed object manager, as in the PSOS design [102, 260]. That paradigm combines four principles of good software engineering - abstraction, encapsulation, inheritance, and polymorphism. Inheritance is the notion that related classes of objects behave similarly, and that subclasses should inherit the proper type behavior of their ancestors; it allows reusability of code across related strongly typed classes. Polymorphism is the notion that a computational resource can accept arguments of different types at different times, and still remain type safe; it permits programming generality and software reuse. (A recent effort to model dynamically typed access controls is given by Tidswell and Potter [373].)
Ultimately, the choices of which of many development methodologies, testing techniques, and assurance methods are used is not particularly critical. What is most important is that software development managers understand the development process, that designers understand the full implications of their designs, and that implementors respect the integrity of the designs when those designs are adequate but that they also recognize when the designs are faulty. The methods and tools can go only so far. Inevitably, it is the people in the process that matter, and they cannot be automated.
Software Architecture in Practice [31], a potentially useful recent book from the Carnegie-Mellon University Software Engineering Institute, considers the business cycle and organizational forces behind software architecture. It presents a management-oriented view of some of the problems that we consider here.
Parnas [77, 278, 277, 279, 288, 289, 280, 286, 281, 285, 282, 287] (listed chronologically) and Dijkstra [93, 94, 95] have for many years written extensively on the modular decomposition of system designs. (Various other authors have written more recently on this subject.) Unfortunately, most commercial systems are seriously lacking in their architectural structure.
The effects of module composition on the corresponding security models have been studied extensively in recent years (e.g., [3, 40, 129, 192, 195, 196, 197, 198, 202, 213, 325, 330, 370, 394, 395]). In many cases, however, seemingly straightforward compositions have unpredicted side effects, in some instances interfering with one another. (A case of supposedly independent cryptographic security protocols interacting unsecurely is given by [153].)
In other efforts less specifically related to security, there has been considerable research in combining models, theories, equational and other logics, term-rewriting systems, and data structures. However, most of these efforts have considered the simplest forms of composition (particularly those involving serial hookups without feedback) and the effects that result from simple combinations of policies or models; these efforts have often been extremely theoretical -- with not much applicability to real system needs such as the implications of composed implementations.
When great care has been taken to achieve interoperable modularity, modular composition is relatively straightforward. More commonly, however, composition is not an a priori design consideration, and composability may be very difficult. Ideally, it should be possible to configure a specific system capable of attaining the desired (sub)set of requirements, parametrically tailored to each specific application. Integration of the chosen components should be attainable with minimum effort, with respect to design, implementation, operation, and maintenance. Composition should address the incorporation of less trustworthy components (e.g., as in Byzantine agreement) as well as compromise of trustworthy components. As applicable, common useful middleware components should be identified from which survivable systems can more readily be configured -- in the sense of a virtual survivable trusted computing base that can survive certain threats despite the presence of a less trustworthy underlying operating system. System adaptability under perceived threats may also be useful.
At the Eighth ACM SIGOPS European Workshop in Sintra, Portugal, in September 1998 (see [24]), a rather awkward debate took place. The stated argument was that the development of robust distributed systems from components is impossible [155]. Although "a marginal majority disagreed" with this proposition, there are strong arguments that emerge from the discussion bearing on why composition is not straightforward in any realistic situations. However, a deeper conclusion that might be drawn from that debate is that we must work much harder to establish criteria under which composition does not compromise robustness, and perhaps even enhances it -- as suggested by the notion of generalized dependence.
[T]he representation of structure is the most important aspect of programming for purposes of formalization.
Bob Barton, May 1963 [30]
Formal methods can play an important role in the attainment of systems and networks that must achieve generalized survivability, in specification, design, and execution. Great improvements in system behavior can be realized when the requirements (such as survivability, security, and reliability) have a formal basis. Similarly, enormous benefits arise whenever design specifications have a formal basis -- especially if they are derived from well-specified requirements rather than the common practice of being established after the fact to represent an ad hoc assembly of already-developed software (sometimes referred to as putting the cart before the horse). Formal design verification then involves formal demonstrations that the specifications are consistent with their requirements, providing no less than required -- and to the extent that the absence of Trojan horses can be demonstrated, nothing unexpected that might be harmful. Verification of designs is difficult for systems that were not designed to be readily analyzed, but can nevertheless be valuable in legacy systems (as in analyses of the risks associated with the Year-2000 problem). Finally, although it is less commonly practiced in software, formal code verification can demonstrate that a given implementation is consistent with its specifications. Formal hardware verification is being used increasingly, and demonstrates the potential effectiveness of formal methods where there are considerable risks (financial or otherwise) of improper design and implementation.
Various formal methods can be valuable in specifying and analyzing requirements, designs, and implementations, as well as in compositionality. Of particular importance in connection with survivability are techniques that can provide formal relationships between different layers of abstraction -- with respect to requirements and specifications alike. The use of formal methods is recommended in particularly critical applications, and can help move the current highly unpredictable ad hoc development process into a much more predictable formal development process. In the long run, use of such techniques can dramatically decrease the risks of system failure. Contrary to popular myth, judicious use of formal methods can also decrease the overall development and operating costs -- especially when the costs of aborted developments (such as the cancellations of the IRS, FAA, FBI systems noted in Section 4.3) are considered, along with the costs of overruns, delays in delivery, and subsequent maintenance.
Judicious use of formal methods can have a very high payoff, particularly in requirements, specifications, algorithms, and programs concerned with especially critical functionality -- such as concurrency, synchronization, avoidance of deadlocks and race conditions in the small, and perhaps even network stability and survivability in a larger context, derived on the basis of more detailed analyses of components. There is no substitute for using demonstrably sound algorithms (e.g., [343]).
Important early work on the effects of composition using hierarchically layered abstractions was part of SRI's Hierarchical Development Methodology effort (see Robinson and Levitt [322]). For some reason, this work is still relatively unknown, although it is vital to formal reasoning about subsystem composition and analysis of emergent properties.
Of particular importance is the formal analysis of requirements -- for example, determining whether a given set of requirements at a particular layer of abstraction is consistent within itself, whether the different sets of requirements at the lower layer are fundamentally incompatible with one another, and whether the requirements at a lower layer are consistent with the requirements at the upper layer. Once such an analysis is done, then it is also beneficial to determine whether system specifications and implementations are consistent with the relevant requirements. (Formal analysis applied to safety requirements is considered in [126].)
It must be emphasized that the most valuable uses of formal methods are in finding flaws and inconsistencies, not in attempting to prove that something is completely correct. However, formal methods approaches are not absolute guarantees, because problems can exist outside of their scope of analysis. For example, suppose that a given analysis does not detect any flaws or inconsistencies in a specification or implementation. It is still possible that the requirements are inadequate (e.g., the specifications could fail to prevent a problem not covered by the requirements), or that the analysis methods themselves could be flawed. For these reasons, extensive testing of developed systems is also important - albeit inherently limited.
Unfortunately, testing is itself inherently incomplete and incapable of discovering many types of problems -- for example, stemming from distributed system interactions and concurrency failures, subtle timing problems, unanticipated hardware failures, and environmental effects. Exhaustive testing over all possible scenarios is basically impossible in any complex system.
Considering that survivability, security, reliability, and fault tolerance are all weak-link properties, formal methods and nonformal testing are both useful approaches in attempting to find the weak links. Neither is adequate by itself. An interesting nonformal approach to fault injection to detect failure modes is given by Voas and McGraw [382]; similar ad hoc approaches are common with respect to red-team attacks in testing would-be secure systems.
Formal methods have been used extensively in the past for security (e.g., [60, 79, 144, 172, 176, 251, 269, 270, 309, 331], fault tolerance (e.g., [67, 131, 163, 180, 206, 227, 228, 274, 293]), general consistency [101], object-oriented programs (e.g., [4]), composability (as noted in Section 5.8), compiler correctness (e.g., [368]), protocol development (e.g., [132, 154, 358]), hardware verification and computer-aided design [363], and human safety (e.g., [126, 341]) but to our knowledge not for survivability, or for security and fault tolerance in combination. One serious attempt at a broader approach comes from the European dependability community, which tends to consider dependability as an all-embracing quality (as noted in Section 1.2.3). A representative example of that approach is found in the work of Gerard Le Lann [170, 171] relating to "X-critical applications", where X could be any qualifier such as life, mission, environment, business, or asset, although his formal methods have thus far been applied primarily to fault tolerance. See the discussion of the role of formal methods in secure system architectures by Neumann [251].
The work of Jon Millen under the project is summarized in Appendix B. With particular relevance to the formalization of survivability, he has generalized earlier security-related work of Catherine Meadows [203] to address the configurability of survivable services. Earlier results of his survivability work are given in a published research paper [214] that characterizes reconfiguration as a kind of flow property that can be formally satisfied. Millen's recent survivability measure work [216] extends the system model introduced in the reconfiguration paper [214] to a structural hierarchy. Components of system services are viewed as services with components of their own. With this additional dimension, one can define dependency of a service on a lower-level service, and look for a lattice-valued measure of survivability for comparing services that may be at different levels. The concepts in the measure paper have been simplified dramatically, yet still lead to a max-min formula for the measure that satisfies the intuitively necessary properties. The work also considers uniqueness properties for the measure and other properties of the hierarchical structure, such as criticality of sets of components.
Other papers were also done by Millen with at least partial ARL support, relating to certificate revocation [211, 217] and reasoning about public-key infrastructures [218]. (Jon Millen is also working under a DARPA contract to formally model and prove properties of network protocols and cryptographic protocols, using SRI's PVS verification system for formal proofs - http://www.csl.sri.com/pvs.html.)
Formal methods are also the basis for methods for belief logics that permit the systematic analysis of cryptographic protocols, stemming from the Burrows-Abadi-Needham BAN logic [66], as well as more recent work by Gong, Needham and Yahalom [115], Meadows [204], Kailar and Gligor [146], Alves-Foss [9], Abadi and Gordon [2], and others. There is considerable other work on formal analysis of cryptographic protocols, including Meadows [204] on key management, Lowe [184] on Needham-Schroeder, and Paulson [291, 292], Mitchell et al. [220], and Lincoln et al. [177] on cryptographic and authentication protocols in general. See also Abadi and Needham's formulation of prudent engineering practice for cryptographic protocols [5]. See also Millen and Ruess [212] for a separation of protocol-independent and protocol-dependent analyses (performed under DARPA contract).
Bellovin [37] shows how formal verification can be used to constrain the code generation process, which can be particularly important in source-available compilers, where consistency between the semantics of the source code and the semantics of the object code is critical, independent of the compiler.
See also High-Integrity System Specification and Design, by Jonathan Bowen and Michael Hinchey [61], which applies formal methods to integrity.
Formal methods can also be used in execution, as in proof-carrying code that can be used to ensure that a critical component has not been tampered with. For example, see George Necula's thesis work [235] and Web site (http://www.cs.berkeley.edu/~necula/), including a hands-on demonstration. (An earlier one-page summary of Necula's work in progress is given in [236].)
Of particular interest in the context of highly survivable systems, formal methods have a potentially vital role in robust source-available software, considered in Section 5.10.
The SRI Computer Science Laboratory formal methods Web site has assembled an extensive collection of URLs (see http://www.csl.sri.com/pvs.html) representing work within CSL and elsewhere in the world on formal methods.
We next consider a challenging alternative to conventional software development.18 Our ultimate goal here is to be able to develop robust systems and applications that are capable of satisfying serious requirements, not merely for security but also for reliability, fault tolerance, human safety, and survivability in the face of the wide range of realistic adversities considered in this report. Also relevant are additional operational requirements such as interoperability, evolvability and maintainability, as well as discipline in the software development process.
Despite all our past research, development of commercial systems is decidedly suboptimal with respect to meeting stringent requirements.
To be precise about our terminology, we distinguish here between black-box (that is, closed-box or closed-source) software in which source code is not available, and open-box software (occasionally called clear-box) in which source code is available (although possibly only under certain specified conditions). Black-box software is often considered as advantageous by vendors and believers in security by obscurity. However, black-box software makes it much more difficult for anyone other than the original developers to discover vulnerabilities and provide fixes therefor. Overall, it can be a serious obstacle to having any unbiased confidence in the ability of a system to fulfill its requirements (security, reliability, safety, and so on, as applicable).
We also distinguish here between proprietary and nonproprietary software. Note that open-box software can come in various proprietary and nonproprietary flavors.
Dependence on black-box proprietary code and proprietary interfaces can have many disadvantages:
Windows 2000 (N 5.0) reportedly will have something in excess of 50 million lines of source code (most of that appears to be kernel code), with another 7.5 million lines of associated test code. It is illustrative of each of these factors. Unfortunately, the totality of code on which survivability and security depend is essentially the kernel and operating system plus potentially all the application software that can be loaded at any time. That represents an enormous amount of code that must be trusted (because it is not trustworthy) in any critical application. (Recall the divide-by-zero in an NT application that brought the Yorktown Aegis missile cruiser to a halt, in Section 1.6.)
Spinellis [361] compares the number of system calls in Windows SDK (1998, 3422 calls) with First Edition Unix (1971, 33 calls), SunOS 5.6 (1997, 190 calls), and Linux 2.0 (1998, 229 calls). The comparison is not flattering to the Windows environment.
A humorous but subliminally serious assessment of the use of commercial off-the-shelf (COTS) systems is given by David Carney [69].
In contrast with proprietary black-box software systems, various forms of open-box software and nonproprietary software offer opportunities to surmount these risks enumerated in the previous section, in various ways.
The benefits of nonproprietary open-box software include the ability of outside good guys to carry out peer reviews, add new functionality, identify flaws, and fix those flaws rapidly -- for example, through collaborative efforts involving people widely dispersed around the world. Of course, the risks include increased opportunities for evil-doers to discover flaws that can be exploited, or to insert trap doors and Trojan horses into the code.
The Free Software Foundation (FSF) uses the term free software to imply that the users and redevelopers of the software have certain freedoms that do not arise with proprietary software -- in particular, freedom to copy and freedom to change; however, the cost of the software may or may not be free, so that there are still opportunities for entrepreneurs in developing and maintaining such software. The Free Software Foundation Website at http://www.gnu.org contains software, projects, licensing procedures, and so on. It includes a treatise by Richard Stallman on "Why Free Software is better than Open Source" (http://www.gnu.org/philosophy/free-software-for-freedom.html). It also defines the FSF General Public License (GPL), which enforces copyright plus copyleft, where copyleft requires that redistribution (with or without change) must not restrict freedom to further copy and change.
The Open Source Movement has registered the term Open Source as a certification mark. The term is specified by the Open Source Definition (http://www.opensource.org/osd.html), although there are no restrictions on the use of software subject to that definition. The requirements of the Open Source Definition specify unrestricted redistribution; distributability of source code; permission for derived works; constraints on integrity; nondiscriminatory practices regarding individuals, groups, and fields of endeavor; transitive licensing of rights; context-free licensing; and no adverse effects on associated software. The Open Source Movement Website is http://www.opensource.org/, which includes Eric Raymond's "The Cathedral and the Bazaar" and the Open Source Definition. Because of these terminology confusions, we use the term "open-box" to denote source-available code, encompassing both free software and Open-Source software.
By referring here to nonproprietary open-box software, we encompass the efforts of both the Free Software Movement and the Open Source Movement. Nonproprietary open-box software is increasingly found in the Free Software Movement (such as the Free Software Foundation's GNU system with Linux) and the Open Source Movement. Both of these movements believe in and actively promote unconstrained rights to modification and redistribution of open-box software.
It is a sad commentary on many commercial and proprietary software developments that some of the most useful, flexible, and robust software components today are nonproprietary open-box software products, often the results of labors of love, and widely available free of charge over the Internet or with minimal encumbrances. (Three examples of nonproprietary open-box software have been particularly valuable in the preparation of this report: the GNU Emacs editor, the LaTeX document system, and Hyperlatex -- which generates html from LaTeX source.)
Examples of open-box software within the Free and Open-Source software communities include GPL-ed software (e.g., The GNU System with Linux, GNU Emacs, GCC, Gnome 2.0, Ghostview, GNUscape Navigator, gzip, Java packages) and Free VSD; not quite GPL-ed software (Perl); non-GPL free software (Free BSD, X windows, Apache, LaTeX, Mozilla, Netscape JavaScript ...); and Open BSD, Net BSD, Hyperlatex, Eazel's Linux graphical shell, ... ("GNU" is a recursive acronym, representing "GNU is Not Unix".) Other licenses besides GPL include MPL and QPL; more variants are likely to emerge in the future.
The roles of open-box software in developing highly survivable systems are a recurring theme in the rest of this report, in light of (for example) the Internet, typically flawed operating systems, vulnerable system embeddings of strong cryptography, and the presence of mobile code. An architectural subquestion involves where trustworthiness must be placed to minimize the amount of critical code and to achieve robustness in the presence of the specified adversities, and that question is addressed further in Chapter 7.
A highly oversimplified question is frequently asked: "Will open-box software really improve system security?" The obvious answer is not by itself, although the potential is considerable. Many other factors must be considered. Indeed, many of the problems of black-box software can also be present in open-box software, and vice versa (for example, flawed designs, the risks of mobile code, a shortage of gifted system administrators, and so on). In the absence of significant discipline and inherently better system architectures, opportunities may be even more widespread for insertion of malicious code in the development process, and for uncontrolled subversions of the operational process.
In attempting to exploit open-box software, we face a basic conflict between (a) security by obscurity to slow down the adversaries, and (b) openness to allow for more thorough analysis and collaborative improvement of critical systems -- as well as providing a forcing function to inspire improvements in the face of discovered attack scenarios. Examples of analytic tools for evaluating open-box source code include
Ideally, if a system is meaningfully secure, open specifications and open-box source should not be a significant benefit to attackers, and the defenders might be able to maintain a competitive advantage! For example, this is the principle behind using strong openly published cryptographic algorithms -- for which analysis of algorithms and their implementations is very valuable, and where only the private keys need to be hidden. Other examples of obscurity include tamperproofing and obfuscation. Unfortunately, many existing systems tend to be poorly designed and poorly implemented, with respect to incomplete and inadequately specified requirements. Developers are then at a decided disadvantage, even with black-box systems. Besides, research initiated in a 1956 paper by Ed Moore [221] reminds us that purely external (Gedanken) experiments on black-box systems can often determine internal state details.
Behavioral system requirements such as safety, reliability, and real-time performance cannot be realistically achieved unless the systems are adequately secure. It is very difficult to build robust applications based on proprietary black-box software that is not sufficiently trustworthy.
The 1956 papers by John von Neumann [384] and by Moore and Shannon [222] noted in Section 1.2 showed how to construct reliable components out of less reliable components. Later work on correct behavior despite some number of arbitrarily perverse Byzantine faults followed along those lines. In that context, building a fault-tolerant silk purse out of less robust sow's ears is indeed possible in some cases. But constructing more trustworthy secure systems out of less trustworthy subsystems does not seem realistic when the underlying components are compromisible, despite efforts such as wrapper technology and firewall isolation.
Whenever achieving security by obscurity is not the primary goal, there seem to be strong arguments for open-box software that encourages open review of requirements, designs, specifications, and code. Even when obscurity is deemed necessary, some wider-community open-box approach is desirable. For software and for system applications in which security can be assured by other means and is not compromisible within the application itself, the open-box approach has particularly great appeal. In any event, it is always unwise to rely solely on obscurity.
So, what else is needed to achieve trustworthy robust systems that are predictably dependable? The first-level answer is the same for open-box systems as well as closed-box systems: serious discipline throughout the development cycle and operational practice, use of good software engineering, rigorous repeated evaluations of systems in their entirety, and enlightened management, for starters.
A second-level answer involves inherently robust and secure evolvable interoperable architectures that avoid excessive dependence on untrustworthy components. Of course, potential risks can be associated with nonproprietary software as well as proprietary software -- for example, relating to the authenticity of the sources and the trustworthiness of the distribution paths. To combat ordinary code hacking as well as the three forms of compromise noted in Section 1.3, a broad-spectrum combination of techniques is desirable, including (for example) cryptographic checksums, trustworthy software distribution channels, and public-key authentication schemes, which together can overcome some of the uncertainty as to the trustworthiness of any code version that you might be using. One of the primary architectures considered in this report involves thin-client user platforms with minimal operating systems, where trustworthiness is bestowed where it is essential -- typically, in servers, firewalls, code distribution paths, nonspoofable provenance for critical software, cryptographic co-processors, tamperproof embeddings, preventing denial-of-service attacks, run-time detection of malicious code and deviant misuse, and so on. A less feasible alternative in terms of today's technology involves much more trustworthy end-user platforms.
A third-level answer is that there is still much research yet to be done (such as on realistic compositionality, inherently robust architectures, and open-box business models), as well as more efforts to bring that research into practice. Effective technology transfer seems much more likely to happen in open-box systems.
Nonproprietary open-box systems are not a panacea. However, they have potential benefits throughout the process of developing and operating critical systems. Impressive beginnings already exist. Nevertheless, much effort remains in providing the necessary development discipline, adequate controls over the integrity of the emerging software, system architectures that can satisfy critical requirements, and well-documented demonstrations of the benefits of open-box systems in the real world. If nothing else, open-box successes may have an inspirational effect on commercial developers, who can rapidly adopt the best of the results. But the possibilities are considerable for coherent community cooperation in the development of nonproprietary open-box software, especially if adequately supported.
Because some of the serious systemic deficiencies are not likely to be overcome in proprietary systems (Section 4.3), it would be highly advantageous to make more systematic use of nonproprietary software, especially if the source code is openly available, and if it can be made more robust than its proprietary counterparts, and if trustworthy distribution paths can be established and used consistently in a trustworthy manner. Also important is the systematic use of nonproprietary interface standards that have been explicitly created with interoperability in mind.
Particularly serious potential problems with Trojan horses might be implanted in variant versions of open-box software. A paradigmatic risk is provided by Ken Thompson's C compiler example [372], noted in Section 1.3. In fact, compilers used to produce critical-system code present some special problems. Bellovin's approach to using formal verification [37] is relevant in demonstrating consistency between source code and object code, which is a particularly thorny problem when insiders (such as Ken Thompson!) are able to tinker with the compiler itself.
It is unfortunate that so few robust open-box security systems exist, particularly because closed-source systems represent a violation of the principle of scrutability (see Section 7.1). In a recent communication, Stallman notes that the GNU Project is working on Free Software for public-key encryption. The GNU Privacy Guard, a free and non-patent-infringing replacement for the non-free program PGP, is already being used. LSH, a free and non-patent-infringing replacement for the non-free program SSH, is in development but not yet ready for use.
The research literature is full of public-key-based authentication protocols, and an important recent demonstration showed that serious authentication cannot be done without some form of public-key crypto [122]. The Diffie-Hellman public-key cryptographic algorithm [92] is now in the public domain. A few simple schemes for login authentication are freely available, such as S-Key one-time passwords. The MIT Athena Kerberos and Berkeley BSD Unix are further examples where security has been a serious concern, although Kerberos has experienced a variety of security flaws. PGP (Pretty Good Privacy) is becoming more widespread as it becomes seamlessly embedded in e-mail environments, although has had some proprietary underpinnings. Some of those products can also be obtained commercially through organizations that provide operational and maintenance support, such as PGP and Red Hat Linux. Indeed, it is not essential that nonproprietary software be available free of charge, and considerable value can be added by commercial enterprises. What is important is that the software be available for open scrutiny, able to be improved over time as a result of an open collaborative process, and able to be subjected to distributional controls to ensure its integrity.
We need significant improvements on today's software, both proprietary and otherwise, to overcome myriad risks (see the RISKS archives, http://catless.ncl.ac.uk/Risks/, or the Illustrative Risks document, http://www.csl.sri.com/neumann/). When commercial systems are not adequately robust, we must consider how sound open-box components might be composed into demonstrably robust systems. This requires an international collaborative process, open-ended, long-term, far-sighted, somewhat altruistic, incremental, and with diverse participants from different disciplines and past experiences. It also requires serious attention to the reasons why composition has been so risky in the past (as discussed in the debate [155] noted at the end of Section 5.8). Pervasive adherence to good development practice is also necessary (which suggests better teaching as well). The process needs some discipline, in order to avoid rampant proliferation of incompatible variants. Fortunately, there are already some very substantive efforts to develop, maintain, and support open-box software systems, with significant momentum. If those efforts can succeed in producing demonstrably robust systems, they will also provide an incentive for better commercial systems.
Overall, we need techniques that augment the robustness of less robust components, public-key authentication, cryptographic integrity seals, good cryptography, trustworthy distribution paths, and trustworthy descriptions of the provenance of individual components and who has modified them. We need detailed evaluations of components and the effects of their composition (with interesting opportunities for formal methods). Many problems must be overcome, including defenses against Trojan horses hidden in systems, compilers and evaluation tools, in hardware, source code, and object code - especially when perpetrated by insiders. We need providers who give real support; warranties on systems today are mostly very weak. We need serious incentives including funding for robust open-box efforts. Despite all the challenges, the potential benefits of robust open-box software are worthy of considerable collaborative effort.
Plans for the collaborative research and development of trustworthy survivable (e.g., robust, secure, reliable) interoperable nonproprietary open-box software components are beginning to germinate. We must seek an open process that encourages the development of systems and components addressing the essential problems defined in this report, and which might initially be called Pretty Good Survivability (PGS). The intent is that, through long-term open collaborative efforts involving research and development communities and universities, PGS could gradually evolve into Very Good Survivability (VGS). At the moment, VGS seems like a dream, but it seems to be feasible if PGS is suitably motivated. It also seems absolutely essential to the future of highly survivable systems, and should be well worth whatever effort it requires.
A discussion group for the encouragement of efforts to produce robust
nonproprietary open-box software (whether "Open-Source" or "Free") that
I formed on 11 November 1998 has had some insightful discussions. (To join,
send e-mail toopen-source-request@CSL.sri.com with the one-line
content
subscribe -- or subscribe [your address] if your desired
address is different from your from: address; Majordomo will accept
contributions for the group only from your specified to: address.)
An interesting discussion of whether open-box software can increase security is found in the position papers for a panel session at the 2000 IEEE Symposium on Security and Privacy, with papers by Steve Lipner [183], Gary McGraw [199], Neumann [258], and Fred Schneider [344]. An additional panel position paper written by Brian Witten, Carl Landwehr, and Michael Caloyannides arrived too late for inclusion in the proceedings, but is available on-line: http://www.csl.sri.com/neumann/witten.ps. Also on the panel was Eric Raymond, who noted that the combined forces of the open-box movement involve 7000 active projects, 750,000 participants, and 150,000 hard-core developers. That represents a very considerable potential force to be mobilized!
A fundamental dichotomy seems to exist between systems that must be safe and reliable on one hand, and secure on the other. In the former case, open-box software is extremely desirable to permit extensive analysis. In the latter case, the ingrained predilection tends to promote security by obscurity -- whether or not it is necessary. Highly survivable mission-critical systems clearly deserve greater scrutiny than afforded by closed-source software, but perhaps may not merit completely open-box software where the attackers clearly have the advantage. Ideally, if a system is secure, it should be possible for the design and implementation to be available. However, many of today's systems are so far from adequate that this ideal seems unattainable. Thus, this dichotomy remains very difficult to resolve adequately.
This section summarizes some of the most relevant papers from a recent NATO conference [229] on Commercial Off-The-Shelf Products in Defence Applications: The Ruthless Pursuit of COTS (in addition to the slides presented by Neumann [257], which are included in the proceedings of that conference, and whose conclusion are summarized at the beginning of this section).
As seen from the excerpts, most of these conference papers reflect fairly skeptical views of developing and configuring mission-critical systems out of conventional mainstream COTS products, with many caveats.
Reliability, fault tolerance, security, and indeed survivability must be conceptually integral to hardware and software, despite the desire to use off-the-shelf weakware as the basis for critical applications. In principle, mainstream concepts should be used where applicable, although their shortcomings must be overcome. Good software engineering practice should be used in applications as well as system development. The entire process of program development should be systematized wherever possible. Formal methods should be applied to particularly critical algorithms and programs.
A particularly thorny area involves the need for metrics permitting the definition and analysis of survivability relevant attributes. On one hand, reliability requirements and fault-tolerance mechanisms are nicely amenable to metrics and probabilistic analysis. On the other hand, security and survivability tend to be much less easily characterized using metrics -- with just a few exceptions. One such exception involves work factors regarding the effort to break a given cryptographic algorithm. However, the simplistic application of such metrics is dangerous. For example, the implementation of a given strong cryptographic algorithm may be trivially compromisable from below, from within, or from outside, because of vulnerabilities in the operating system or the application in which the cryptography is embedded. Another example is an attempt to come up with the security of a given operating system. In general, given all the known flaws, the would-be security is typically easily penetrated; furthermore, the likelihood of unknown flaws should make any quantitative measures of security suspect. Nevertheless, the appropriate use of metrics is desirable.
As described in Section 4.3, the supercomputing field has suffered in the past from a serious case of myopia. Some of the lessons that can be drawn from that experience are directly applicable to the need for highly survivable systems and networks.
Several potentially useful research directions are also noted below, in Sections 5.17 and 9.2.
This report does not attempt to replicate the vast literature of techniques for fault tolerance. For example, techniques for increasing system reliability in response to hardware faults and communications failures are explored in general in [43, 96, 123, 161, 169, 246, 293, 311, 314, 356]. Failure recovery in the context of Tandem's NonStop Clusters is considered by Zabarsky [393], representing a serious step toward systemic fault tolerance. Some significant recent research of Kulkarni and Arora relates to compositionality properties of fault tolerance [22, 159] and the somewhat canonical decomposition of fault-tolerant designs into detectors and correctors [23].
Once again demonstrating the desirability of a confluence of requirements and a corresponding confluence of techniques for combatting security and reliability problems along the lines of the reconvergence of availability requirements in Figure 2, consider the requirements for data integrity in the sense of no-unintended-change shown at the nodes designated by a sharp (#) in the figure. Data integrity can be enhanced through cryptographic integrity checks (typically to protect against malicious alterations) or error-correcting coding techniques (typically to protect against accidental garbling). However, an interesting recent special-purpose use of coding for detecting malicious tampering as well as accidental errors in once-writable optical disks is given by Blaum et al. [44], taking advantage of the asymmetry inherent in certain once-writable storage media in which writing can change the state of a bit only in one direction (e.g., from a not previously written zero bit value to a written one bit, but never the reverse). This is another example of a crossover implementation that can simultaneously address different sets of subrequirements stemming from otherwise independent-seeming major requirements. In such cases, considerable benefit can be obtained by recognizing the commonality among otherwise independent subrequirements and then providing a unified treatment in the design and implementation.
Many techniques exist for the a priori analysis of system behavior, based on consideration of requirements, design specifications, implementation, and operational procedures. These techniques may be formal (see Section 5.9) or informal. Examples of such techniques are
In addition, evaluation of the processes that underlie system development may possibly be of interest. Although such process certification does not necessarily say much about a specific development, it may be useful in weeding out the outliers who are completely unqualified -- if the evaluation is itself meaningful:
Although the primary emphasis of this report is on system and network architectures, operational practice is absolutely critical to survivability. Today's systems and networks place enormous burdens on system administrators and security personnel. Ideally, systems and networks should be designed and implemented to increase the manageability of operations, and the requirements for operations should be included up front, as noted in Section 3.4. Indeed, any cleanliness and controllability inherent in architectures can play a major role in improving the operational practice. The approaches discussed earlier in this chapter and the structural concepts examined in Chapter 7 can help. Also important are monitoring facilities that are accurate, timely, and visually understandable. Thus, including operational requirements among the desired system characteristics is important from the outset.
An important approach to controlling system and network behavior involves real-time detection and analysis of potentially undesirable deviations from expected behavior, considered in Section 5.15.
As noted in Section 4.1, there is a great need for the ability to provide real-time detection and analysis of system and network behavior, with appropriate real-time responses -- from the coordinated perspective of survivability and its subtended requirements. There has been considerable work on this topic for more than a decade.
SRI has pioneered work on rule-based expert system analysis and statistical analysis, through IDES (Intrusion Detection Expert System [189]) and NIDES (Next-Generation IDES [11, 12, 142, 139]). The current work on EMERALD (Event Monitoring Enabling Responses to Anomalous Live Disturbances) [182, 304, 305] is the current extension of IDES and NIDES to monitor network activity. Overall, we know of no efforts other than EMERALD that are oriented toward the ability to detect problems arising in connection with generalized survivability. (See http://www.csl.sri.com/intrusion.html.)
Of course, many other institutions have been developing systems addressing various aspects of the intrusion-detection problem, typically using either rule-based techniques or statistical analyses, but in most cases not both, and usually dealing with users of individual systems or local networks. See Edward Amoroso's new book [10] for an introduction to the field. Many papers are worth reading, including [63, 81, 125, 156, 157, 303, 340]. Bradley [62] considers the effects of disruptive routers. In addition, only a few efforts have addressed fault detection in this context -- for example [140, 193, 208].
Schneier and Kelsey [349] have developed a cryptographically based step toward the securing of audit logs against tampering and bypassing.
Another form of real-time analysis involves dynamic network management. Network management should also be integrated with real-time anomaly and misuse detection and real-time reconfiguration as a result of detected problems.
Standards are important, but can also be extremely counterproductive if poorly conceived or misapplied. Chapter 6 considers the existing and emerging evaluation criteria. Appendix C summarizes some of the Department of Defense efforts to standardize architectures and security services. In particular, Section C.1 considers the attempt to impose standardization through the Joint Technical Architecture (JTA); Section C.2 considers the DoD Goal Security Architecture (DGSA); Section C.3 considers the Joint Airborne SIGINT Architecture (JASA) Standards Handbook (JSH).
Criteria for security are considered in Section 6, including the U.S. Department of Defense Trusted Computer Security Evaluation Criteria (TCSEC), the European (ITSEC) and Canadian counterparts (CTCPEC), and the new international Common Criteria.
The British Ministry of Defence has established some rigorous standards for safety-critical systems [375, 376], although it is not clear to what extent they have actually been used.
International cooperation is inherently a difficult problem, complicated even further in the case of computer system standards and criteria by needs for transborder interoperability, reciprocal evaluations that can be (or indeed, must be) honored in multiple countries, different national needs and perceptions (e.g., on the relevance of multilevel security, and how to achieve it), and so on. There are no easy ways to accomplish such cooperation, but making sure everyone is talking with everyone else is essential.
As an international nongovernmental organization, the Internet Engineering
Task Force (IETF) (http://www.ietf.org) has
been particularly effective in establishing Internet standards, with
considerable emphasis on interoperability and change control. (The IETF
strongly favors open interfaces, and tolerates proprietary standards only
where open standards also exist.) In addition, other standards are
emerging from the Open Group
(http://www.opengroup.org),
the IEEE
(http://www.ieee.org),
the Association for Computing
(ACM)
(http://www.acm.org),
and other organizations. However, the IETF process must work harder to
achieve better protocols that encompass more of the survivability issues
addressed in this report.
The certification and licensing of programmers is also being considered in some circles as an approach to standardizing developer skills. See recent position papers by Parnas [284] and Neumann [255] from the 2000 IEEE International Conference on Requirements Engineering.
Historically, research has provided some powerful techniques for increasing survivability, reliability, and security, although much of the potentially most valuable research has not found its way into commercially available personal computer products, and only occasionally into computer systems. Serious research is still needed to address some of the remaining deficiencies.
In this report (see Section 7.2), we pursue the notion of generalized multilevel survivability (MLX, introduced in Section 1.2) that draws on past experience with multilevel security, multilevel integrity, and multilevel availability. We do this not with the expectation that system developers will rewrite all their systems, but rather with the expectation that the MLX concept might provide some useful architectural insights.
The mobile-code paradigm is an important topic for future R&D, with respect to security and reliability. (See Section 7.4.)
Research results also suggest some dramatic changes in high-performance computing, which if properly applied could reverse the rather negative historical perspective noted in Section 4.3. For example, two recent software-based efforts are illustrative of a kind of new thinking that could be very beneficial. Each is a different new paradigm that has considerable potential in the development of high-performance systems.
Specific recommendations for future research and development are given in Section 9.2. The R&D recommendations of the President's Commission on Critical Infrastructure Protection are summarized in Section 9.7.
Issues such as reliability, security, and system survivability need to become a part of a broader educational curriculum and institutional training programs. The same is true of an understanding of vulnerabilities, threats, and risks. The desired audience includes not just programmers and system developers, but also administrators, legislators, system procurement agents, and even prospective users. However, in the final analysis, education and training cannot be effective unless effective system solutions are available to be learned. Appendix A outlines course curricula for survivability.
Chapter 7 of the report of the President's Commission on Critical Infrastructure Protection [194] recommends the establishment of some new organizational entities. It is worth reviewing them, because they bear directly on the problems of infrastructure survivability.
This seems to represent a considerable increase in the institutionalization of an already highly bureaucratic situation, especially in that the PCCIP has focused largely on the so-called critical national infrastructures and seriously underplayed the importance of the computer-communication infrastructures. Very little in the PCCIP report suggests that the survivability, security, availability, or reliability of the computer-communication and information infrastructures would gain significantly from these organizational entities. In addition, there is still no constituency for the non-DoD non-U.S.-Government user public, as has been pointed out on various occasions -- including in the 1990 in the Computers at Risk study [72].
In the meanwhile, President Clinton has reconstituted the PCCIP concept by creating a Critical Infrastructure Assurance Office (CIAO), and created the office of the National Coordinator for Security, Infrastructure Protection, and Counter-Terrorism, which will be responsible for a broad range of policies and programs related to cyberterrorism. In addition, the FBI is establishing a National Infrastructure Protection Center (NIPC) to counter individuals and organizations that commit computer crimes. (See Presidential Decision Directives PDD 62 on counterterrorism and PDD 63 [73], aimed at reducing the vulnerabilities.)
Unfortunately, the U.S. Government has had little success in enticing certain major commercial developers to do the right thing -- namely, to significantly increase the survivability, security, and reliability of their systems. That shortcoming may ultimately be the limiting factor -- despite the hopefulness expressed in some of the recommendations of our report.
Also, unfortunately, the Government seemingly has not had much success in achieving a minimal level of competence in avoiding security risks (as evidenced by Deputy Secretary of Defense John Hamre calling the Cloverdale kids' cookbook attack the "most organized and systematic the Pentagon has seen to date" -- see the Risks Forum, volume 19, issue 60 (http://catless.ncl.ac.uk/Risks/19.60.html) or in dealing with computer systems at all (as evidenced by the huge effort to surmount the Y2K challenge -- see Congressman Stephen Horn's Y2K report card, http://www.house.gov/reform/gmit/y2k/index.htm, which was updated quarterly for several years prior to Y2K and showed slow progress for a long time). It is a huge challenge merely getting competence levels in security up to the levels suggested in Fighting Computer Crime [275].
Further information on Web sites for some of the above organizations and for the Carnegie-Mellon Software Engineering Institute's Computer Emergency Response Team (CERT) are given in Appendix D (Some Noteworthy References) at the end of this report.
The currently existing evaluation criteria frameworks are not yet comprehensively suitable for evaluating highly survivable systems and networks. Even with regard to security by itself, the existing criteria are incomplete and inadequate. In addition, there is almost no experience in evaluating systems having a collection of independent criteria that might contribute to survivability, and the interactions among different criteria subsets are almost unexplored outside of the context of this report. Nevertheless, a good set of security criteria -- if it existed -- would be very valuable.
This section considers the emerging Common Criteria effort, which is attempting to overcome many of the deficiencies of its precursors, the DoD Trusted Computer Security Evaluation Criteria Rainbow series (e.g., the TCSEC [233], TNI [231], and TDI [232]), the European ITSEC [99], and the Canadian CTCPEC [68].
The evolving Common Criteria document has been undergoing extensive review, preparatory to being submitted as an ISO standard. See http://csrc.nist.gov/cc for the latest draft documents and progress toward establishing the Common Criteria. (Version 2.1 was posted 31 January 2000.)
Any set of requirements, and indeed any generic (abstract) systems architecture, must not overly constrain the implementations of systems intended to satisfy those requirements. This is an inherent danger in the TCSEC, but less so in the other criteria because they are frameworks for evaluation rather than prescriptive requirements. In addition, the ITSEC and CTCPEC effectively distinguish functional requirements from assurance requirements, and that useful distinction has been continued in the Common Criteria.
There is also a serious danger of underconstraining the resulting systems and networks. For example, the Rainbow series of trusted-system criteria may overconstrain implementations with respect to the bundling of criteria elements at a particular evaluation level (e.g., A1, B3, B2, B1, C2), but also underconstrain the implementations with respect to many other criteria elements that are omitted -- relating to networking, application security, modern authentication (e.g., using one-time tokens instead of fixed reusable passwords), fault tolerance, reliability, real-time performance, interoperability, reusability, software engineering, and the development process, to name just a few. These aspects are absolutely fundamental to the successful procurement and development of suitable systems and networks that can satisfy stringent requirements. Simply adhering to very superficial but allegedly definitive generic requirements and criteria (Orange Book, Red Book, and others), procurement cookbooks, and Chinese menus for system configuration is doomed to failure. In addition, despite the enormous proliferation of the Rainbow series in multitudinous colors, the TCSEC is intrinsically incomplete, for a variety of reasons.19 For example, it deals primarily with confidentiality in centralized systems (failing to keep up with the last decade of progress in distributed systems and networked systems, and not adequately treating integrity and the prevention of Trojan horses and other pest programs). It is monolithic, in that it lumps together functionality and assurance, and within functionality criteria lumps together requirements that are more rationally treated somewhat independently. For example, the notion of fixed passwords does not make much sense in systems that demand high assurance. Cryptography is basically ignored. The TCSEC does not adequately concern applications and systems configured out of other systems, stressing primarily trusted system components. It also typically ignores survivability, reliability, fault tolerance, performance, interoperability, real-time requirements, system engineering and software engineering, system operations, and many other issues that are essential to the development and configuration of survivable systems and networks.
The desire to be able to configure critical systems out of off-the-shelf components and particularly off-the-shelf software is commendable, but largely a fantasy. Commercially available infrastructure components (operating systems, database management systems, networking software, and application software) are typically not able to fulfill stringent requirements. In some cases extensive customization is required, and is still inadequate. Furthermore, considerable expertise is required to operate and maintain the resulting systems. The concept of turn-key systems satisfying extremely complex critical requirements is unrealistic.
What is needed in the future is more efforts aimed not at cookbooks but rather at constructive documentation of worked examples providing the following:
The appropriate use of structure is still a creative task, and is,
in our opinion, a central factor in any system designer's responsibility.
Jim Horning and Brian Randell, 1973 [133]
Intelligently conceived system structure remains seriously undervalued. The appropriate use of structure was already recognized as a creative task in Multics (e.g., see [75]) in 1965, and its benefits in that system were very considerable in the process of development and subsequent evolution. Reflecting on the Horning-Randell quote above, it is still a vital creative task in the new millennium -- perhaps even more so than before. However, it must be accompanied by thorough understanding of the desired requirements and their implications, as well as detailed engineering to ensure that the implementation does not undermine what the structure has attempted to achieve.
The emphasis in this report is on architectural structures and structural architectures that are independent of particular system and network designs and independent of specific implementations, but still firmly rooted in the broad set of requirements for survivability. In this way, we avoid getting mired in the distinctions among the Joint Technical Architecture's "technical architectures", "operational architectures", and "systems architectures" (see Appendix Section C.1) -- all of which lack a true sense of architecture - as well as the DoD Goal Security Architecture's abstract, generic, specific, and logical architectures and its so-called security architecture (see Appendix Section C.2).20
Some of the architectural structures considered here involve relatively untrusted end-user systems combined with ultra-dependable trustworthy servers out of which structural architectures can be conceived, and from which survivable systems and networks can be developed or configured. Of particular interest are architectural structures that include authentication servers, file servers, and network servers, which under generalized dependence can overall provide highly survivable and highly secure systems and networks.
Some of the short-term candidate architectures can eventually be made more survivable by gradual evolution. Unfortunately, some of the longer-term approaches that could achieve truly high survivability require more revolutionary new directions; they are much more farsighted, and consequently less likely to win popular support among those system developers who are bent on lowest-possible-cost solutions. The recent not-too-surprising discovery by NASA that their "faster, cheaper, better" approach is a resounding failure is a clear illustration of the risks. Faster and cheaper are generally not better when systems are mission critical. (For example, see RISKS-20.84 http://catless.ncl.ac.uk/Risks/20.84.html and .86 http://catless.ncl.ac.uk/Risks/20.86.html for some discussion on the Mars Lander, and Leveson [174] for an analysis of the role of closed-box proprietary software in mission-critical systems.)
This chapter considers multilevel-secure systems as well as single-level systems. Single-level systems are ubiquitous. Multilevel-secure systems are desired by the Department of Defense, but introduce many problems of their own -- some of which can interfere with the needs for survivability, particularly if not addressed systemically. Ideally, multilevel-secure systems should be configurable with only minimal dependence on multilevel-secure components, rather than requiring pervasive high-assurance MLS throughout every end-user component. Furthermore, the single-level systems should be integrally related to the multilevel systems, rather than completely different families of architectures. If an architecture is properly conceived, a multilevel system should not have to be significantly different from its single-level counterparts. This is a goal that has not previously been pursued, and runs counter to the dictates of the Trusted Computer Security Evaluation Criteria (TCSEC) discussed in Chapter 6. However, it seems highly advisable if MLS systems are ever to become practically achievable. Nevertheless, the inherent incompleteness of MLS requirements must be addressed, in particular with respect to the requirements for integrity and survivability.
Several fundamental architectural principles are essential to effective architectural structure, each of which can considerably improve overall survivability. Not surprisingly, these principles have deep roots in the security and software-engineering communities. In particular, see the 1975 paper of Saltzer and Schroeder [337], in which many of the following items are found.
For a variety of reasons, these organizing principles can contribute to increased system and network survivability -- if they are consistently applied and if they are properly implemented. Note that abstraction, layering, encapsulation, object-oriented approaches, and policy-mechanism separation all can contribute to greater interoperability, reusability, long-term system evolvability, and security. The principles of separation of concerns and least privilege can also substantially improve operational security and reliability.
These principles can also contribute to improved analysis. In particular, formal methods can be used to analyze requirements, specifications, and implementations. However, such analyses can be greatly simplified by the use of structural concepts -- especially layering, abstraction, encapsulation, policy-mechanism separation, and domain separation. For example, the mappings among layers of formally specified abstractions in SRI's Hierarchical Development Methodology [322] are capable of inducing enormous simplifications in the formal proof process for large systems.
Approaches that properly address the mobile-code problem demand significant improvements in the information infrastructure. The notion of portable computing is clearly a forcing function on system architectures, and can result in significant improvement of the survivability of the entire system and network complex if consistently reflected in the architecture.
Ideally, modern software engineering should encompass these organizing principles, although in practice it is frequently not used in a sufficiently disciplined manner to take advantage of them.
In direct response to the 1990 Computers at Risk report of the National Research Council [72], an effort is proceeding to develop and promulgate a set of Generally Accepted Systems Security Principles (GASSP) (http://web.mit.edu/security/www/gassp1.html), and to establish an International Information Security Foundation (I2SF). Many of those principles are relevant to survivability as well, but are clearly not enough by themselves.
Several main structuring concepts are of particular interest, each of which has the potential of inducing considerable discipline on architectures employing the structural concepts of Section 7.1, and thereby enhancing survivability. The intent of this section is to summarize various approaches, some of which are competing with one another, others of which may be used in combination. There are clearly tradeoffs that must be considered carefully before embarking on particular architectural directions -- tradeoffs among survivability issues including security, reliability, functionality, performance, and assurance of application behavior.
One of our most important considerations throughout this report is that the application functionality is fundamental, not just the operating systems kernels and trustworthy extensions. One of the primary failures of the security kernel movement in the 1980s was that it overendowed the kernels and TCBs.
An alternative approach to a portion of the ML problem is described by Kang, Froscher, and Moskowitz [148] at the Naval Research Laboratory, and is also considered. The NRL work aims at what is in effect a highly distributed MLS TCB incorporating a variety of efforts to integrate MSL systems, including a one-way-flow architecture (e.g., [85], a Pump [149] and SINTRA on the server side, and two COTS-based switched workstations on the client side, allowing them to operate at different levels of multilevel security). One of the clients is the Starlight Interactive Link[14], developed by the Australian DSTO. The other is the COSPO (Community Open Source Program Office) Switched Workstation, developed by MITRE, and approved for use between Unclassified and Top Secret levels of classification. The latter scheme makes extensive use of integrity checks and authentication, particularly across MLS boundaries. However, neither the NRL work nor Starlight addresses the integrity problems that accompany upward flow from a lower to a higher MLS level -- the MLS-only view allows rampant acquisition of Trojan horses and other pest programs. The NRL effort is aimed primarily at allowing the facile reading of lower-level information, flowing only from the server to the client, and does not represent a full MLS environment.
What is highly desirable in the long run is the establishment of a family of logical system architectures encompassing the best aspects of those approaches that are really applicable to survivability. For example, we can conceive of systems whose architecture is based on minimizing trustworthiness where possible, using MLS kernels and TCBs in MLS servers where multilevel functionality is essential, using stringent domain separation where multiple users are necessary (but perhaps not in one-user personal computers or in dedicated workstations -- other than the layered isolation of the user from applications, applications from the operating systems, and so on), using dynamic loading of authenticated mobile code from trusted sites, and using explicitly compensating system structures where that approach can have high payoffs. Such an architecture might actually achieve the desired effects of robust MEIIs; however, the goal of achieving MEIIs is derivative; it would be the result of having developed suitable system architectures, and is not meaningfully achievable by itself.
Multics (Section ArchStruct), PSOS (Section SoftEng), SeaView (Section GenDep), and EMERALD (Section 5.15) are excellent examples of the role of design structure, because developers of each of those systems took great pains to advance the state of the art in constructive structure and good software engineering practice. (See the Noteworthy References cited in Appendix D.)
The vast majority of commercial personal-computer operating systems (notably, those from Microsoft) are a joke when considered with respect to network security and availability. Some of the Unix platforms have matured to the point at which early jokes about "Unix security" being an oxymoron are a less serious concern, although the ability to misconfigure Unix systems is still a critical practical problem.
In conventional centralized multilevel-secure systems, it is customary to talk about the scope of the security perimeter that encompasses the enforcement of multilevel security -- typically a multilevel-security kernel plus some (often large) amount of trusted code in the TCB. However, such a security perimeter does not encapsulate the security concerns, only a selected few abstracted issues relating to multilevel security. As soon as we consider distributed systems and highly networked environments, the so-called security perimeter typically encompasses major components and functionality (such as compilers, run-time libraries, browsers, bytecode interpreters, servers, and untrustworthy remote sites), and in some cases may actually be essentially unboundable -- especially when it includes the entire Internet, every telephone in the world, and electromagnetic interference from unanticipated sources.
In all such systems -- whether centralized or distributed -- with any generality of purpose, there is no survivability perimeter in the sense that all critical survivability issues can be circumscribed. Nevertheless, several of the structural architectures considered in Section 7.6 are capable of providing survivable systems and networks in the absence of secure operating systems for end-user systems. However, authentication becomes a very critical issue, as does the need for trustworthy bilateral authenticated paths.
Whoever thinks his problem can be solved using cryptography doesn't understand his problem and also doesn't understand cryptography. Attributed by Roger Needham to Butler Lampson, and attributed by Butler Lampson to Roger Needham.
Strong cryptographic algorithms and their robust nonsubvertible implementations are absolutely fundamental to the attainment of system security and survivability. Shared-key cryptography (also called secret-key cryptography, and symmetric-key cryptography -- because the same key is used for encryption and decryption) is helpful but in itself not sufficient for achieving confidentiality, integrity, some detection of denials of service, and in preventing various forms of computer misuse. Public-key cryptography (also called asymmetric-key cryptography, because different keys are used) is particularly well suited for key management (key agreement, key distribution), integrity, and authentication.
Unfortunately, even the best cryptographic algorithms can often be trivially compromised from outside, from within, and from below, in a variety of ways. Although a few widely publicized challenges have resulted in exhaustive searches through the entire key space (DES and RSA are two examples), many cryptographic algorithms or their implementations have been broken without resorting to exhaustion. For example, systems that employ key-recovery and key-escrow techniques have intrinsic trapdoors and are likely to be subject to compromise of one form or another -- by trusted insiders, but also potentially by outsiders. Hardware-implemented cryptography is often considered to be more secure than software-implemented cryptography, but that is not necessarily the case. (For example, see [249].)
In any event, cryptography and cryptographic keys represent an important example of the potential concentration of high-value targets that should be minimized by the hardware-software design wherever possible.
The Diffie-Hellman and Rivest-Shamir-Adleman (RSA) asymmetric-key algorithms are extremely important examples of public-key algorithms. (For background, see Schneier's Applied Cryptography [347].)
Key management presents some very difficult problems. As one example of a desirable approach, the Diffie-Hellman public-key technique [92] provides an elegant means for key agreement without a shared private key ever having to be transmitted. Agreement is reached with each party using its own private key and the other party's public key (or in multikey algorithms, the other parties' public keys), based on partial information shared among the parties from which each can construct the desired shared key for subsequent symmetric-key communications.
Only through careful and comprehensive study of vulnerabilities such as those noted in Section 4.1 (e.g., see [6, 7, 15, 84, 158, 347]) is it possible to develop algorithms, protocols, and implementations that are significantly less vulnerable to attack and misuse. Perhaps here more than in any other area of security, the ultimate truth is that there are no easy answers when it comes to the nonsubvertibility of cryptographic applications. (See [348] for an extensive debunking of the myth that cryptography is in itself a panacea.)
In general, there are significant needs for end-to-end encryption between cooperating entities. However, there may also be needs for additional link encryption among internal network nodes to permit proper handling and monitoring of network traffic headers while protecting that information in transit.
A broad range of standard specifications for public-key cryptography [137] is currently being defined under IEEE auspices. It encompasses public-key cryptography that depends on discrete logarithms, elliptic curves, and integer factorization. In its present advanced draft form, it already appears to be an extraordinarily useful document, and could go a long way toward unifying the cryptographic product marketplace.
The future of cryptographic applications is always a little uncertain. Algorithms for factoring large prime products and tricks for computing discrete logarithms may emerge. Digital signatures may be compromisable before their intended expiration date. The risks must be clearly recognized, with systems and applications designed accordingly.
One of the most important subsystems that is not easily attainable today in commercially available systems involves a set of highly survivable trustworthy distributed authentication mechanisms that can support a variety of authentication policies, providing nonspoofable authentication despite the presence of potentially untrustworthy components -- such as end-user terminals and workstations, Web servers, intermediate network nodes, and possibly flawed embeddings of cryptographic algorithms. We attempt to characterize some Byzantine-like authentication servers that can operate securely despite such uncertainties, and examine some of the more realistic variants. Thus, there must be multiple authentication servers for higher availability, internal redundancy and cross-checking for reliability, and extensive use of cryptography for confidentiality, integrity, and nonspoofability. An important proposal for a public-key certificate-based Simple Distributed Security Infrastructure (SDSI) is given by Rivest and Lampson [321] along with a Secure Public Key Infrastructure (SPKI) [98]. See also Abadi's formalization of SDSI's linked local name spaces [1]. There is a long history of work on systemic authentication, going back to Needham and Schroeder [238] beginning in 1978 (with discovery of flaws, fixes, and other advances since then [184, 220]), MIT's Kerberos [39, 219, 239, 364] beginning around 1987, and the Digital Distributed System Security Architecture (DDSSA) [110, 165] around 1990. SDSI and SPKI are an outgrowth of that particular chain of intellectual history from the research community. Somewhat independent work stems from the European work on the SESAME project [276].
An absolutely critical weak link that must be overcome is the absence of an adequate trusted path from the user to the various systems being used, particularly in personal computers but also in workstations. Recent work at the University of Pennsylvania by Arbaugh et al. [19] based on their earlier work on the AEGIS Secure Bootstrap [20] presents an approach that enforces a static integrity property on the firmware and a combination of induction, digital signatures, and modifications to the control transitions from certain major modules such as call and jump instructions. This approach is called Chaining Layered Integrity Checks (CLIC). (See also related work on trustworthy automated recovery [21], which shares many of the same problems with the trusted path.)
The lack of an adequate trusted path in the reverse direction, from systems to users, also represents a weak link in many systems. User authentication is intended to ensure that a particular user is authentic, but does not guarantee the integrity of the path.
Closely related to, and in some sense a generalization of, the trusted-path problem is the need for assurance that any resource (data, source code, object code, firmware, and hardware) has not been tampered with or otherwise altered. This problem exists whether we are concerned with firmware in local systems, sensitive (that is, survivability-, security-, or reliability-relevant) components of operating systems, middleware, application software, and -- very critically in networked Web environments -- applets or other executables that come from external sources. This resource-assurance problem is also very important in backup and retrieval, and in reconfiguration. Essentially any out-of-band change to the system or network state is vulnerable to compromise. Workable approaches may use a combination of digital signatures, cryptographic integrity protection, dedicated tamperproof hardware (particularly for cryptographic functions), proof-carrying code, and other forms of dynamic code checking.
Given appropriate uses of cryptography (Section 7.3.2), systems can be designed in which file servers need not be trustworthy with respect to confidentiality or integrity, although there would still be reliability problems relating to guaranteed availability and security problems relating to preventing denials of service and ensuring that the accessed file servers are authentic. This is true even with multilevel security (e.g., [310]). However, given the possibility of a file server being compromised from within or from below, it is usually desirable to ensure that some basic trustworthiness is provided by the file servers themselves, particularly for integrity and prevention of denials of service.
Although name servers are (rather naively) often thought not to be security critical, they are certainly critical with respect to preventing accidental and intentional denials of service and to achieving overall system and network survivability. Inaccessibility of system and network name servers can have devastating effects, and organized attacks on those servers are particularly nasty. Correctness of data is also a serious problem. Name servers can also be instrumental in attacks that use inferences that can be drawn from the information they provide.
When certain functionality is not sufficiently trustworthy, it may be useful to encapsulate it within some sort of wrapper that attempts to enhance the trustworthiness of the wrapped component. This is another manifestation of the notion of generalized dependence considered in Section 1.2.5, in trying to make a silk purse out of a sow's ear. However, wrapper technology is always likely to be susceptible to compromise from within and from below, and if not perfectly implemented may also be subject to compromise from outside. Furthermore, there is strong evidence that safety-critical and mission-critical systems cannot be achieved through wrapping flawed COTS systems (for example, see [174, 390]). For further discussion of attempts to use COTS products in critical applications, see the proceedings of the April 2000 Brussels NATO conference [229] on Commercial Off-The-Shelf Products in Defence Applications: The Ruthless Pursuit of COTS, summarized in Section 5.10.3 of this report.
As noted in several sections of Chapter 5, we need much better protocols -- more robust, more secure, more highly available, and so on -- with dramatic improvements over existing ones (TCP/IP v6, ftp, telnet, udp, smtp) that are soundly implemented. Robust networking protocols must also be embedded in sound operating systems; otherwise, they are compromisible -- from outside, from within, and from below. It is conceivable that some wrapper technology could provide some short-term help, but given the dramatic increases in bandwidth, it is clear that improved protocols are needed anyway. The needs of survivability must be more actively recognized in ongoing IETF and other protocol efforts.
Given appropriate uses of cryptography, new network protocols or assiduous overlays on the existing protocols, and careful implementation on relatively secure platforms, it is in principle possible to develop network servers -- routers, gateways, guards, firewalls, filters, and other interface devices -- that can be adequately trustworthy. Multilevel security requires either extraordinarily trustworthy operating systems on which to mount the network servers, or else multiple single-level servers (e.g., [310]). Network servers must be designed to provide confidentiality, integrity, protection against denials of service, and fault tolerance.
Firewalls are in some sense a special case of a wrapper in which the intent is to wrap an entire network. In that case, the firewall policy is typically to prevent sensitive things from getting out, and to prevent bad things from getting in. Existing firewalls today tend to suffer from being inadequately secure, attempting to enforce policies that are unsound, and being operationally misconfigured. However, in principle, a firewall that is well designed and well configured and whose policies are well conceived can in fact be highly beneficial. The best of the bunch today is probably the Secure Computing Corporation Sidewinder, which permits strong typing to be included in the firewall security policy.
Unfortunately, today's firewalls and routers are seriously vulnerable to denial-of-service attacks. Consequently, it is clear that any sensible architecture must address their survivability against all the likely threats. In principle, firewalls should be able to seal off internal networks from outside attackers. In practice, firewalls are porous. In practice, firewalls are often configured to allow potentially devastating e-mail to enter and executable Web content to be requested (for example, Microsoft Office attachments, Word Macro viruses, ActiveX, Java, JavaScript, and PostScript). In practice, internal systems depend on outside functionality. In practice, denials of service against the outside routers are problematic. Furthermore, given the porous nature of firewalls, inside routers are also vulnerable. This is a case in which practice does not make perfect.
Ideally, serious peer-to-peer authentication and both end-to-end and link encryption throughout might be helpful in reducing some of the primary risks of denial-of-service attacks. In practice, no one seems willing to pay the ensuing performance penalties.
The only sane short-term solution seems to be to seal off internal networks from the Internet via stringent firewall policies that block all threatening incoming traffic that might affect the internal hosts and routers. In the long term, new architectures and network protocols are urgently needed.
Section 5.15 suggests the need for real-time analysis of system and network behavior and appropriate timely responses. As one illustrative example of how this might be achieved, we believe that our existing EMERALD (Event Monitoring Enabling Responses to Anomalous Live Disturbances) environment [182, 266, 304, 305] can be readily generalized to address detection, analysis, and response with respect to significant departures from expected survivability-relevant characteristics, including reliability, fault tolerance, and availability in addition to the current emphasis on security. The primary EMERALD statistical component recognizes anomalous departures from expected normal behavior, whereas the EMERALD signature-based component is rule based and recognizes the presence of potential exploitations of known or suspected vulnerabilities. In addition, a new hybrid Bayesian component takes on some of the advantages of both. The EMERALD resolver passes the results of the analytic engines on to a response coordinator (under development) and to higher-layer instances of EMERALD running with greater scope of awareness. Work is just beginning on a response coordinator that will provide specific real-time advice for defensive actions and other remediation. With only slight extensions, a generalized EMERALD could also mediate conflicts that might arise among the different subtended survivability requirements.
EMERALD is at present oriented primarily toward detection, analysis, and response related specifically to security misuse of computer networks. Its basic architecture observes good software engineering practice, abstraction, and internal interoperability, and is naturally well suited to this generalization effort -- which we believe will fill a major gap in attaining flexible system architectures for survivability. EMERALD is also participating in the Common Intrusion Detection Framework (CIDF) effort, which will enable considerable interoperability among different analysis systems and reusability of individual components in other environments. In addition to security-related applications, we are contemplating integrating EMERALD with a classical network management facility, which would provide real-time information relating to configuration management, performance management, fault management, security management, and accounting management.
We refer to EMERALD here primarily to illustrate the potential applicability
of real-time monitoring and analysis in the maintenance of survivable
systems. EMERALD has the oldest ancestry and the greatest generality of
approach (following its predecessors IDES and NIDES). (See
http://www.csl.sri.com/intrusion.html
for extensive background on our work in this area.) It has also had
considerable emphasis devoted to its software engineering. Of particular
relevance here is a 1999 paper entitled Experience with EMERALD to
Date [266]
(http://www.csl.sri.com/neumann/det99.html
and
(http://www.csl.sri.com/neumann/det99.ps.
The requirements for monitoring must also be considered carefully, as was done in the 1985 document [89] that established the security requirements for IDES implementations. Among security needs, such a system must be able to establish a strong resistance to attack (including spoofing and denials of service) and must protect the sensitivity of the audit data and derived information. Other requirements include generality of approach and applicability to new domains, scalability, flexibility, adaptability, reusability of components, interoperability with other systems, and the ability to operate at differing levels of abstraction of audit data and results. See [266] for a discussion of the importance of good software-engineering practice in the development of monitoring and analysis systems.
With reference to the systemic inadequacies outlined in Chapter 4, Table 6 summarizes some of the major hurdles that must be addressed for each component of the previous subsections. The table considers the integrity, confidentiality, availability, and reliability of various functional entities, as illustrative of the challenges. It suggests that we still have a long way to go.
Table 6: Typical Architectural Limitations
Functionality Integrity Confidentiality Availability Reliability Application Inability to Inability to Inability to Inability to software rely on lower rely on lower rely on lower rely on lower layers; lack of layers; lack of layers; lack of layers; lack of correctness correctness correctness correctness User platforms, Weak security, Weak security, Many crashes, HW/SW OSs, middleware, especially when especially when file errors, reliability browsers, etc. networked; networked upgrade woes often poor OS spoofable Networking Flawed designs Flawed designs Weak protocols, Weak protocols, and protocols and code and code code bugs code bugs Cryptography Poor embedding, Poor embedding, Mass market Subject to bit (for integrity, compromise from key exposures, hindered by errors, key authentication, within/below; bypasses; government unavailability, encryption) gov't policies gov't policies crypto policies synch problems Authentication Reliance on Reliance on An outage can Inconsistency subsystems fixed reusable fixed reusable shut down all among multiple passwords passwords dependent users authenticators Trusted paths Generally Generally Denials of Generally and resource nonexistent nonexistent service nonexistent integrity or very weak or very weak problematic or very weak Servers (file, Weak security; Weak security; Outages and HW/SW ftp, http, lacking crypto, lacking crypto, service denials, reliability e-mail) authentication authentication incompatibilities often poor Wrappers Compromise from Cannot hinder Service denials Much depends below/within, insiders on wrappers on wrapper even outside may be easy reliability Firewalls Compromise from Weak policies, Service denials Nonreplication below/within, weak security on firewalls leads to service even outside may be easy outages Monitoring, Bypassable, Sensitive Not robust, Algorithms analysis, alterable, data may be subject to typically response spoofable exposed service denials incomplete
In light of the extensive set of limitations in the present technology exhibited in Table 6 (and the table gives only a sampling), we reiterate that survivability and its subtended requirements of security and reliability are fundamentally weak-link problems. The table very simply conveys the message that weak links abound. Although we tend to seek defense in depth, we seem to achieve only weakness in depth. The real challenge is to overcome the limitations suggested by Table 6.
Survivability clearly depends on many people during the development cycle. However, one of the largest collection of weak links and vulnerabilities emerges only during the operational phase, where survivability depends on operators, administrators, and users. As noted above, administration of cryptography presents enormous risks. We remind our readers once again that although the main emphasis of this report is on architectures, the best architecture of all may be compromisible if it does not properly address the operational aspects. The approach of this report stresses the importance of a total-system orientation, with respect to the entire enterprise as a system of systems, a network of networks, and views networks as systems. This approach recognizes the critical dependence on many people, even when the architecture is specifically designed to tolerate human foibles.
A significant paradigm for controlled execution involves the use of mobile code -- that is, code that can be executed independently of where it is stored.21 The most common case involves portable reusable code acquired from some particular sources (remote or local) and executed locally. From a different perspective, it could involve local code executed elsewhere, or remote code executed at another remote site. Ideally, mobile code should be platform independent, and capable of running anywhere irrespective of how and from where it was obtained. Used in connection with the principles of separation of domains and allocation of least privilege, dynamic linking, and dynamic loading with persistent access controls, this paradigm provides an opportunity for the secure execution of mobile code, and represents a very promising approach for achieving ultrasurvivable systems.
Of course, you can have major integrity, confidentiality, availability, denial of service, and general survivability risks involved in executing arbitrary code on one of your systems, or even on other systems operating on your behalf. The existence of mobile code whose origin and execution characteristics are typically not well known necessitates the enforcement of strict security controls to prevent Trojan horses and other unanticipated effects. In certain cases, it may be desirable to provide repeated reauthentication and validation, plus revocation and cache deletion as needed. (See Section 7.4.2.) When combined with digital signatures and proof-carrying code to ensure authenticity and provenance, dynamically linked mobile code provides a compelling organizing principle for highly survivable systems.
In principle, properly implemented environments for executing mobile code can contribute to survivability in various ways:
A highly survivable overall mobile-code architecture can be aided by a combination of trustworthy servers, encrypted network traffic, digital signatures, proof-carrying code, and other components and concepts discussed in Section 7.3. Three contemporary doctoral theses provide important contributions to the establishment of such an architecture:
Background on understanding code mobility rather independently of survivability and security issues is given in a useful article by Fuggetta et al. [108] (in a special issue of the IEEE Transactions on Software Engineering on mobility and network-aware computing). Formal methods are also particularly relevant to mobile code, because of the critical dependence on type safety -- for example, the formalization of dynamic and static type checking for mobile code given in [319].
An extraordinary compilation of articles on various aspects of the mobile-code paradigm has been assembled by Giovanni Vigna, and published by Springer Verlag [381]. This book (which contains copious references) reflects most of the potential problems with mobile code, and suggests numerous approaches to reducing the risks. Considering the enormous potential impact, this book is mandatory reading for anyone trying to use the mobile-code paradigm in supposedly survivable systems. Following is a brief summary of the book.
The notion of a confined execution environment goes back at least as early as Multics. The nested Multics rings of protection were useful for protecting the system against its applications and protecting its applications (e.g., software, data) against their users. However, the rings are also relevant to system survivability; a problem in ring 1 could not bring down the system-critical code in ring 0, but might crash a user process; a problem in ring 2 might abort a user command but would not crash the user process; a problem in an outer ring might typically signal an error return without otherwise affecting running processes.
Important subsequent research came from Michael Schroeder [351, 353] (his doctoral thesis on domains of protection and mutual suspicion grew out of the Multics project) and Butler Lampson [166], with later work by Paul Karger [150] on preventing Trojan horses in a conventional access environment (that is, not multilevel secure). Ideally, it should be possible to control execution in such a way that nothing adverse can possibly happen. In practice, of course, the challenges are much more difficult.
The Java Virtual Machine (JVM) is an example of an execution environment designed to encapsulate the execution of code that can be dynamically obtained and loaded from arbitrary sources, subject to suitable security controls. Together with the Java Development Kit (JDK) [114, 116], JVM takes a significant step toward limiting bad effects that can take place in execution of an applet obtained from a potentially untrustworthy site. This is an example of a controlled execution domain whose intent is to radically limit what can and cannot be done, irrespective of the source of the applet. Systems designed to support secure and reliable execution of trustworthy mobile code can have an inherent potential stability. However, JVM is not yet a total solution, in that it is defined only in terms of single-user systems; it does not provide protection of one user from another simultaneous user.
The specific execution environments provided by Java, the Java Virtual Machine, and the Java bytecode have some serious potential security problems, largely attributable to the enormity of the code base and the fact that a very large portion of that code must be considered to be within the effective trusted computing base -- which to a first approximation includes most of the run-time support, the bytecode verifier, the local operating system, the browser software, the servers from which code is obtained, and the networking software. Although this enormous security perimeter could be shrunk somewhat by techniques discussed below, the security perimeter for JVM applet security is very large.
In concept, many problems can be made worse by the presence of mobile code in heterogeneous networked systems. However, a well-engineered and properly encapsulated virtual machine environment has the potential of overcoming many of the risks that might otherwise arise in the use of arbitrary programming languages and the execution of arbitrary code. We believe that the mobile-code paradigm has enormous potential with respect to survivability (and the potential to withstand forced system crashes, loss of security, accidental outages, and so on), because of the roles it can play in inducing a survivable architectural structure. But that in itself forces us to think about the problems it raises.
There is of course a conflict between the desire to provide extensive functionality and the need to constrain or confine the functionality to make it secure -- in order to help the overall computer-communication environment be survivable under attacks.
Of particular relevance here are the analyses of Drew Dean [87] and Dan Wallach [385] of the Java Security Manager (JSM), which is intended to be a security reference monitor that mediates all security-relevant accesses. A reference monitor is supposed to have three fundamental properties: (1) it is always invoked (nonbypassability), (2) it is tamperproof, and (3) it is small enough to be thoroughly analyzed (verifiability). Unfortunately,
In addition, both Dean and Wallach note that the Java language itself and its implementations do not have any auditing facility, and thus completely fail to satisfy the TCSEC accountability and auditing requirements.
One of the problems associated with the mobile-code paradigm is that it is a pull mode rather than a push mode of operation. It could be advantageous to have subsequent improvements automatically downloaded, although that also creates potential integrity problems. Furthermore, there are cases in which it may be desirable or even necessary to revoke instantaneously all accesses to existing copies of a particular version of a program or data. However, existing browsers generally prefer locally cached versions to newer versions. The instantaneous revocation problem was investigated in the 1970s in the context of capability-based architectures (e.g., [100, 102, 113, 147, 151, 260]), beginning with David Redell's thesis [316, 317].
Under Redell's scheme, revocable access requires an extra level of indirection through a designated master capability, so that revocation of all copies of a given object could be effected simply by disabling the given master capability. (We could also contemplate a distributed set of equivalent capabilities that could in a practical sense be disabled simultaneously.) To achieve a similar effect in the context of the WOVOERA mobile-code paradigm without undermining the performance benefits that result from caching, some sort of compromise push-pull mechanism is needed to ensure the currency of a locally cached object. Although instantaneous revocation seems intrinsically incompatible with local caching, various alternatives exist. One approach would be a single currency bit that is updated periodically, and checked whenever access from a cached version is attempted -- forcing deletion of the cached object through dynamic reloading whenever the currency bit has been reset.
The basic work on proof-carrying code (Section 5.9) comes from George Necula [235]. Each code module carries with it proofs about certain vital properties of the code. The validity of the proofs can be readily verified by a rather simple and relatively fast proof checker. If the proofs indeed involve critical properties, in principle any adverse alterations to the code (malicious or otherwise) are likely to result in the proofs failing.
The survivable execution of untrustworthy mobile code depends on the successful isolation of the execution, preventing contamination, information leakage, and denials of service. What is needed in system and network architectures involves a combination of language-oriented virtual machines as in JVM [116], sandboxes [114, 191], differential dynamic access controls [386], mediators, trusted paths to the end user, less-permissive bytecode verifiers, cryptography [339], and whatever authentication, digitally signed code, proof-carrying code [235, 236], and other infrastructural constraints may ensure that the risks of mobile code can be controlled. Not surprisingly, many of these requisite mechanisms are desirable for most meaningfully survivable environments, but the desirability of the mobile-code paradigm makes the potential vulnerabilities much more urgent -- and indeed dramatizes the generic problems when interpreted appropriately broadly.
In several previous sections of this report, we have noted the enormous potentials for wireless end-user computing. Particularly in combination with the thin-client user platforms discussed in Section 7.4.4, wireless communications are already beginning to revolutionize the computer-communication technology. However, the potential risks to integrity, confidentiality, and availability are also enormous, and consequently serious architectural and operational approaches are necessary. An aggressive combination of link encryption and end-to-end encryption is only part of the solution. Protection against denials of service is essential. Under normal operations, conventional encrypted communications may be adequate. However, under concentrated attacks, much more must be done. The use of spread-spectrum communications, with multiple paths and redundant bandwidth with error-correction capabilities are desirable, appropriate to the perceived risks. The desirability of highly survivable wireless environments that can also function stand-alone in times of crisis is an important example of the need to integrate and coordinate the requirements for security, reliability, and performance for the systems and networks in the large when confronted with the full range of adversities noted in this report. If the stated requirements and the ensuing system architectures do not anticipate those needs from the outset, adequate satisfaction of the requirements will be unattainable.
Toward our stated goal of developing and configuring highly survivable systems and networks, a fundamental challenge is to constructively take advantage of the structuring principles (Section 7.1) and architectural structures (Section 7.2) discussed above.
This section considers some representative types of architectures, with particular emphasis on selective-trustworthiness architectures that inherently satisfy many of the structuring principles. Note that the mobile-code paradigm (Section 7.4) and the multilevel-survivability paradigm can be compatibly implementable within a single architecture -- and indeed should be, considering the rampant popularity and enormous advantages of mobile code. However, the existence of mobile code forces us to confront problems that otherwise have lurked in the shadows for many years.
Because multilevel systems are less closely allied with what is commercially available today, and because our multilevel concept draws heavily on single-level components, the single-level concept is considered first. However, realistic multilevel-secure architectures are feasible, given a little common sense in approaching nonconventional architectures.
We consider next the relatively simpler case of conventional single-level systems and networks. We attempt to define precisely which components of a structural architecture must be trustworthy with respect to each of the various dimensions of trustworthiness -- for example, integrity, confidentiality, prevention of denial of service and other aspects of availability, guaranteed performance, and reliability. Table 7 summarizes some of the primary architectural needs that can contribute to overall survivability, in response to the identified limitations of Table 6. Throughout Table 7, it is evident that there is a pervasive need for good cryptography, by which is implied strong algorithms whose implementations and system embeddings are properly encapsulated, nonsubvertible, tamperproof, and reliable.
Table 7: Architectural Needs
Functionality Integrity Confidentiality Availability Reliability User PC/NC Run-time checks, Access controls; Alternative Constructive OS, application cryptographic authentication, sources, redundancy, code, browsers integrity seals, trusted paths, system reliable accountability good encryption fault tolerance hardware Networking Better protocols, Better protocols, More-robust More-robust and protocols sound embeddings sound embeddings defensive defensive good encryption, good encryption protocols, protocols, tamperproofing embeddings embeddings Cryptography Tamperproof and Robust algorithms Dedicated Trustworthy (for integrity, nonsubvertible and protocols, hardware, sources, authentication, implementations nonsubvertible sensible U.S. superimposed encryption) implementations crypto policy! error correction Authentication Spoofproofing, One-time crypto- Alternative Distributed subsystems replay prevention, based tokens, fault-tolerant consistency, (e.g., with crypo tokens, in some cases authentication redundancy strong crypto) tamperproofing biometrics servers in hardware Trusted paths Trusted path to Trusted path to Dedicated Self-checking, and resource users and servers, users and servers, connections, fault tolerance, integrity integrity as in good encryption alternative dedicated user OSs (above) trusted paths circuits Servers (file, Superior security, Superior security, Mirrored Constructive ftp, http, good encryption, good encryption, file servers, redundancy, e-mail, etc.) authentication, authentication, robust selfchecking better protocols, better protocols fault-tolerant protocols tamperproofing protocols Wrappers Spoofproofing Sensible Authentication, Robust OSs, and Firewalls policies trusted paths wrappers, firewalls Monitoring, Tamperproofing, Enforcement of Continuity of Selfchecking, analysis, nonbypassability, privacy concerns service, strong fault tolerance, response avoidance of (much sensitive connectivity, coordinated net- overreactions data involved) self-diagnosis work management
In considering the attainment of system-, network-, and enterprise-wide multilevel survivability (including appropriate MLS, MLI, MLA) without multilevel-secure end-user systems, we draw heavily on past work at SRI [267, 310] and ongoing work at NRL (e.g., [148]).
The basic strategy is conceptually simple. It mirrors some of the early work on multilevel-secure systems, with several fundamental differences:
Given this type of architectural structure, a relatively simple informal analysis can determine whether it is at all likely that the architecture can enforce the desired partial orderings dynamically. In other words, are there any gross violations of MLX dependence on less trustworthy subsystems? If so, can generalized dependence in some way adequately overcome the potential violations? Formal methods are not required in the basic stages of defining the architecture, although they could be useful later on in providing implementation assurance.
Overall, we should not expect that, apart from MLS (which may be fundamental to certain applications), there would be a rigorous enforcement of strict partial ordering among the other attributes of MLX (namely, MLI and MLA) throughout the entire enterprise, and rather that mechanisms invoking generalized dependence can compensate for what would otherwise be violations of partial ordering.
One of our most fundamental issues concerns the extent to which trustworthy systems can be developed despite the presence of end-user systems of varying degrees of untrustworthiness. This issue is very important in single-level systems (Section 7.6.1), and is even more important in the context of multilevel systems with minimized trustworthiness (Section 7.6.2). The following questions relate to end-user access to networked distributed environments that are intended to be highly survivable:
In the case of multilevel operations, it might be deemed acceptable to assume that the user of a potentially untrustworthy end-user system could operate at a permissible secrecy level selected by its (apparent) user -- if user authentication can be done in a nonsubvertible way that provides adequate trustworthiness, and if there is some sort of trusted path to the desired operating system (including integrity checks to ensure that the operating system had not been subjected to tampering). For example, a level of user authenticity could be provided by physical enclosures and personal recognition, or by an out-of-band biometric technique or a trusted-path cryptographic authentication with dedicated nontamperable hardware. If that assumption is not justifiable, the particular user of that end-user system would have to operate at an unclassified level. In any case, it must be realized that high-end authentication such as unforgeable and nonreplayable biometrics may still be attacked by compromises from within and below. It must also be remembered that multilevel security does not address integrity issues (particularly those encompassed by multilevel integrity).
In the case of multilevel operations, the particular user of that end-user system would have to operate at an unclassified level, or else submit to authentication by a trusted multilevel authentication server before any further nonlocal access is possible. If the local authentication is not trustworthy and the local operating system is not trustworthy, no access to multilevel resources should be permitted.
In the case of multilevel operations, no further access should be permitted if any multilevel security is required across the network, or if the integrity of the networked remote entity cannot be assured, or if an entity-in-the-middle attack is possible.
In the case of multilevel operations, no further access should be permitted.
In the case of multilevel operations, no further access should be permitted.
Thus, we are faced with essential trade-offs. If the local end-user operating systems and their trusted paths cannot be trusted, trustworthiness must not be assumed and the architecture must transfer trustworthiness to selected servers -- where permitted. If the local authentication cannot be trusted, trustworthiness must be transferred to authentication servers. If the local networking software cannot be trusted, then trustworthiness must be transferred to selected network servers. On the other hand, if certain servers are not sufficiently trustworthy with respect to certain dimensions, then again trustworthiness in those dimensions must be transferred to servers that are more trustworthy.
If multilevel security is to be enforced, a sufficiently single-level secure local end-user system is necessary, nonbypassable local end-user authentication is necessary, multilevel-trustworthy networking is necessary even if local operation is single level (although cryptographic techniques can be used to ensure that if keys are distributed according to MLS requirements, no adverse flows can arise), and the trusted path and local system integrity must be noncompromisible.
Certain of the dimensions of survivability are more critical than others. For example, system integrity is generally paramount. If system integrity can be subverted, then it is usually easy to subvert confidentiality, availability, and reliability as well. On the other hand, denials of service can often result (whether intentionally perpetrated or accidentally triggered) without first subverting system integrity. Thus, it is advisable to consider each dimension in its own terms to determine the extent of the interdependencies.
By layering the mechanisms for protection, fault tolerance, and other aspects of survivability, and invoking the notion of generalized dependence, we might hope that a sufficiently survivable system could eventually be attained. However, access to sensitive MLS data should not be permitted whenever the end-user authentication cannot be guaranteed (with reasonable certainty), and also whenever the local end-user operating system can be compromised. Strict dependence on less trustworthy MLI resources should be avoided in any event.
You cannot make a silk purse out of a sow's ear.
Another reminder of the old saying, still valid
The architectural structures analyzed in Chapter 7 can be effectively implemented, and survivable systems can be effectively configured using some commercially available components plus the additional subsystems characterized in Chapter 5 to fill the gaps identified in Chapter 4. Whereas the proverbial silk purse is clearly unattainable from the sow's ear (despite a few system purveyors who would have you believe otherwise), it must be recognized from the outset that substantive risks will remain no matter what we do, because we are living in the real world rather than some idealized fantasy world. The challenge is to minimize those risks by relying on an architecture that is structurally sound, implementations that are robust where they need to be robust, operational practice that does not undermine the given requirements, and real-time analysis tools that can rapidly identify early threats to survivability and respond accordingly.
Finally, based on the foregoing discussion, we are ready to put the pieces together. A somewhat simplistic summary of the desired process is as follows:
A suitable architecture for survivable networks of survivable systems might typically be one that encompasses those of the following desiderata deemed suitable for the given application in the case of dedicated systems, or the full range of expected applications in the case of systems that are more general-purpose.
Detailed analysis of the candidate architecture is then needed to evaluate the appropriateness of the architecture, and detailed analysis of the feasibility of its successful implementation is needed to determine whether it is worth pursuing the particular architecture further. This is clearly an iterative process whenever the analysis determines inadequacies in the candidate architecture. In some cases, it may be appropriate to pursue alternative candidate architectures or variants thereof in parallel -- at least until most of those alternatives can be discarded in favor of clear winners.
A suitable baseline family of architectures is now evident from the preceding text of this report.
Implementing systems that fit this kind of baseline architecture remains a huge challenge for the future. But such a strategy is likely to be the only successful path to the future whenever systems with critical survivability requirements are needed. The exact role that open-box software might play remains to be determined, particularly in obtaining robust components that otherwise do not exist today. Its potential is considerable and must be explored in detail, supported by financial and other incentives.
Such a strongly partitioned network architecture with strict isolation and very controlled information flow across well-defined and well-administered boundaries is absolutely essential to any private intranets that are used for mission-critical purposes. There is nothing extraordinary about military needs as far as the technology is concerned. Digital commerce shares many of the needs for survivability, and particularly robustness, integrity, and prevention of denials of service. Many businesses have similar needs. In the absence of easy solutions to those needs, everyone is operating at risk. The U.S. Government needs to take a much stronger role in identifying the critical requirements and finding ways to improve procurement and incentives to ensure that those requirements be fulfilled. The first step involves clear recognition of the critical requirements and dramatic improvements in education.
The emerging Tactical Internet is an ideal environment in which to explore the merits of the highly principled architectural and operational approaches outlined in this report. The Tactical Internet represents a combination of extremely critical requirements, including real-time performance and extraordinarily flexible rapid reconfiguration, in addition to its stringent requirements for security and reliability.
Learning is not compulsory.
Neither is survival.
W. Edwards Deming
The currently existing popular commercially available computer-communication subsystems are fundamentally inadequate for the development and ready configuration of systems and networks with critical requirements for generalized survivability. Numerous good ideas exist in the research community, but are widely ignored in commercial practice. However, although it is theoretically possible to design dependable systems out of less-dependable subsystems or to design more-dependable critical components, it is in practice almost impossible to achieve any predictable trustworthiness in the presence of the full spectrum of threats considered here -- including incorrect or incomplete requirements, flawed designs, flaky implementations, and noncooperating physical environments offering electromagnetic interference, earthquakes, massive power outages, and so on. Furthermore, the almost unavoidably critical roles of people throughout these systems and networks raise serious operational questions -- especially relating to less-than-perfect individuals who may be dishonest, malicious, incompetent, improperly trained, disinterested, or who might in any way behave differently from how they would be expected to act in an assumed perfect world. These and many other considerations that are naturally subsumed under our notion of generalized survivability make the problems addressed here extremely challenging, important, and timely.
The challenge here is to do the best we can in the foreseeable future, and to characterize steps that must be taken that will enable us to achieve better systems in the more distant future. There is still a lot to learn about survivability and how to attain it dependably. We hope that this report will be a significant step in that direction.
Unfortunately, the quest for simplicity and easy answers is pervasive, but very difficult to combat. In this report, we attempt to address the deeper issues realistically and to inspire much greater understanding of those issues.
Our main recommendations are summarized here, recapitulating the Executive Summary. Specific directions for research and development are discussed in Section 9.2.
Section 5.17 considers the role of research and development. This section outlines some specific R&D directions for the future.
[O]ur heads are full of general ideas that we are now trying to turn to some use, but that we hardly ever apply rightly. This is the result of acting in direct opposition to the natural development of the mind by obtaining general ideas first, and particular observations last; it is putting the cart before the horse. ... The mistaken views ... that spring from a false application of general ideas have afterwards to be corrected by long years of experience; and it is seldom that they are wholly corrected. That is why so few men of learning are possessed of common sense, such as is often to be met within people who have had no instruction at all.
Arthur Schopenhauer, Excerpted from Parerga and Paralipomena, 1851, included in Schopenhauer Selections, edited by DeWitt H. Parker, Scribners, New York, 1928, with minor modernization of the translation by PGN.
Many lessons can been gleaned from experience with past system developments, both successful and unsuccessful. These experiences can help us to calibrate the appropriateness of the various principles scattered throughout this document.
The work of Henry Petroski [297, 298] (a civil engineer at Duke University) is noteworthy. Petroski has often observed that we tend to learn very little from our successes and that we generally can learn much more from our failures. Unfortunately, the experiences documented extensively by Neumann [250] suggest that the same mistakes tend to be made over and over again -- particularly in computer-related systems.
Here are a few conclusions, in part tempered by watching the negative experiences in the on-line Risks Forum, and in part from highlighting the constructive aspects of some past system efforts. If Schopenhauer and Petroski are as fundamentally correct as it appears they are, we must learn more from our experiences, good and bad.
The following itemization of lessons learned amplifies some overall strategies for achieving highly survivable systems and networks, but is also applicable to less critical environments.
The relative roles of experiential knowledge and general principles are considered in the context of education in Appendix A.
Chapters 7 and 8 provide guidelines, principles, and architectural structures for designing and implementing systems and networks with stringent survivability requirements. Experience tends to support the belief that highly principled and architecturally motivated designs have a much greater likelihood of converging on systems and networks that can successfully meet stringent requirements, and that can evolve gracefully to accommodate changing requirements. In particular, highly structured designs, domain separation, encapsulation, information hiding, cleanly defined interfaces, formal models of composition and interconnectivity, and many other concepts explored in this report can all have very significant payoffs.
This report is only part of the picture with respect to what is ultimately needed. Requirements are of little use if they are not explicitly honored in architectures, implementation, evolution, and operation. One important set of activities relating to the establishment of a sound basis for survivable systems and networks involves experimentation with testbeds that can demonstrate the feasibility of the architectures and concepts described in this report. Such an effort is already under way within the Army Research Laboratory Survivable Systems and Networks Laboratory (SSNL), under the direction of Anthony Barnes at Fort Monmouth. Among other things, SSNL is investigating and experimenting with features that can enhance system and network survivability, relating to operating systems, network protocols and networking software, IP security, hardware, routers and servers, and environmental considerations. Specific directions include tactical networks, simulated tactical testing, virtual private networks, and robustifying operating systems. Linux and related systems and network architectures are highly relevant, using nonproprietary protocols and open-box software wherever possible, and creating some new infrastructures as well. Portable computing and mobile code are both of enormous relevance to DoD and particularly the Army. SSNL plans on partnering with NSA, SEI, DISA, Army CECOM, and other organizations, as desirable. The SSNL effort and other activities of this type are urgently needed, and supporting them is highly recommended.
Despite the best intentions on the part of the architects of systems and networks having strong survivability requirements, many vulnerabilities are still likely to remain. Hardware is always a potential source of system failures (and, potentially, physical attacks), either transient or unsurmountable without physical repair. The software implementation process is fundamentally full of risks. Operationally, knowledgeable system and network administrators are chronically in short supply, and their role in maintaining a stable environment is absolutely critical. In addition, opportunities are rampant for malicious Trojan horses and just plain flaky software -- especially in mobile code and untrusted servers. Penetrations from outside will always be possible in some form or another, and misuse by insiders remains an enormous source of risks in many types of systems. Furthermore, because systems and networks tend not to be people tolerant, users are inevitably a source of risks -- no matter how defensively the user interfaces may appear to be. These expected residual shortcomings must be anticipated. Real-time analysis for misuse and anomaly detection still remains desirable as a last resort, even in the best of systems.
The recommendations of Section 9.2 provide a considerable sharpening of some generic recommendations of the report of the President's Commission on Critical Infrastructure Protection [194]. It is interesting to contrast what comes out of the survivability-driven concepts of this report with the funding areas suggested by the Commission:
The recommendations of our report address many research and development aspects of items 1, 2, 3, and 5, while at the same time focusing more broadly on survivability rather than just security. Item 6 is also important, although somewhat peripheral to the focus of our efforts. Because it does not create an architectural forcing function (other than the motherhood idea that we should reduce the number of vulnerabilities that must be reported), we simply assume that emergency response teams will exist in a more effective form than at present.
Item 4 causes us some concern. Although risk avoidance is in essence
what this report is all about, and static risk assessment is important (see
Section 5.13), the notion of decision support tools is
potentially dangerous. Many of those tools that purport to manage
risks actually encourage us to ignore certain risks rather than prevent
them. However, those tools are often based on incorrect assumptions, and
frequently ignore the interactions or dependencies among different
requirements, components, and threat factors. Reliance on support tools to
perform risk management is very dangerous in the absence of deep
understanding of the risks, their causes, and their consequences. On the
other hand, if we had that deep understanding, we might have better systems,
and the risks could actually be avoided to a much greater extent -- rather
than having to be managed! Nevertheless, an interesting potential attempt
to quantify risks and to balance defending against perceived threats with
what can be considered acceptable risks is given by Salter et
al. [336]. The Software Engineering Institute at Carnegie-Mellon
University is working on a taxonomy of risks
(http://www.sei.cmu.edu).
A general discussion of the risks of risk analysis itself can be found in a brief but incisive contribution of Bob Charette ([250], Section 7.10, pages 255-257). For example, overestimating the risks can cause unnecessary effort; underestimating the risks can cause disasters and result in reactive panic on the part of management and affected people; estimates of parameters are always suspect; perhaps most important, there is seldom any real quality control on the risk assessment itself.
Our three years of effort on this project represent only a beginning of what is likely to be a long quest. There are many short-term measures that can be taken that would greatly improve the ability of systems and networks to satisfy critical requirements. However, many long-term issues remain to be addressed.
We have outlined many research and development concepts that are highly relevant to the specification, design, development, and operation of highly survivable systems and networks. The architectural directions pursued here integrate those concepts (including generalized dependence and generalized composition) and provide a strong basis for systems that accommodate mobile code, portable user platforms and robust execution platforms, minimal critical dependence on untrustworthy components, and operational environments that are highly reconfigurable and adaptive. However, the problems discussed herein need to be confronted multidimensionally, both technologically and nontechnologically.
Much work remains to be done to demonstrate the practical applicability of this approach, but we believe that we have broken some new ground. Once again, we note that the architecture and implementation considerations are vital, but that operational aspects are also, as well as improving education and awareness. The state of the art has not improved appreciably, and the risks have actually worsened relative to the threats, vulnerabilities, and increased dependence on flaky technologies. Thus, the basic problems we face are becoming ever more important.
This is not a case of Just Add Money and Stir. Pervasive understanding is needed of the depths of the problems and the urgent needs for solutions. Although some significant progress can be made in the short term, commitment to long-term advances is essential.
Although our ARL project has now ended, I hope that efforts can be continued
in the spirit outlined here on many of the fronts for which survivability
matters most - for example, supporting governmental operations, critical
infrastructures, and digital commerce, and enhancing human well-being.
The words of Albert Einstein again seem pithy, this time in circumscribing the rather modest intent of the author of this report -- despite the enormity of the underlying challenge:
Finally, I want to emphasize once more that what has been said here in a somewhat categorical form does not claim to mean more than the personal opinion of a man, which is founded upon nothing but his own personal experience, which he has gathered as a student and as a teacher.
Albert Einstein, Out of My Later Years, The Philosophical Library, Inc., New York, NY, 1950, p. 37.
That very humble statement succinctly expresses my sentiments about the evolution of this report over the past three years.
I am especially grateful to Paul Walczak for his valuable assistance and strong encouragement, and to Tony Barnes for his deep interest in the project and his long-term interactions [29]. Tony almost single-handedly stimulated awareness of information survivability issues within the Army and the DoD in the mid-1990s, and Paul went on from there with extraordinary energy and enthusiasm. When Paul retired shortly before project completion, Tony re-emerged as our official Government contact.
I am greatly indebted to my SRI colleagues Jonathan K. Millen and Phillip A. Porras for many stimulating discussions over the years. Jon made some notable research contributions on the project. (See Appendix B.) Phil's technical and leadership roles in the EMERALD effort have been truly marvelous and very productive.
Sami Saydjari joined us at SRI in the last three months of the project, and generously contributed some incisive comments on the final drafts of this report. I had interacted with him over the years during his previous incarnations at NSA and DARPA, and have always greatly appreciated his insights. (Sami spearheaded DARPA's survivability program, including many projects related to anomaly, misuse, and intrusion detection.)
Drew Dean was a valuable resource during the first phase of the project, when he spent two summers in CSL and kept in touch while working on his Princeton PhD thesis [87]. (I was on his committee.)
I am totally delighted with Otfried Cheong's Hyperlatex
http://www.cs.uu.nl/~otfried/Hyperlatex),
which enabled the LaTeX form of this document to be robustly transformed
automagically into its almost perfect html equivalent. (The LaTeXsource
was also used to generate the .dvi file from which the PostScript and pdf
versions of the report were generated, attaining three mobile formats from
one source.) Peter Mosses has my perpetual thanks for patiently shepherding
me through my initial use of Hyperlatex.
Hyperlatex is just one wonderful example of Free Software that is copyleft under the Free Software Foundation's General Public License (GPL). Of course, I am also pleased to have used Richard Stallman's GNU Emacs and Les Lamport's LaTeX in the production of this document, as well as Linux, all of which are outstanding examples of open-box software.
I appreciate the considerable feedback that I have received from members of the Free-Software and Open-Source movements regarding how to greatly increase the robustness of open-box software, including their contributions to the informal robust open-box e-mail distribution list noted in Section 5.10.2.
Peter G. Neumann, Menlo Park, California, June 2000
Phase Topic Sources A Fundamentals of Programming Languages Prerequisite (Type 1) or integrated unit (Type 2) B Fundamentals of Software Engineering Prerequisite (Type 1) or integrated unit (Type 2) (see X for possible follow-on) C Fundamentals of System Engineering Integrated material (Type 1), but not widely taught today D Fundamentals of Operating Systems Prerequisite (Type 1) or integrated unit (Type 2) E Fundamentals of Networking Prerequisite (Type 1) or integrated unit (Type 2) S Introduction to survivability: concepts, Chapter 1(Type 1 or 2) threats, risks, egregious examples S Specific Threats Chapter 2 (Type 1 or 2) S Survivability Requirements Chapter 3 (Type 1 or 2) S Systemic Deficiencies Chapter 4 (Type 1 or 2) S Systemic Approaches Chapter 5 (Type 1 or 2) S Evaluation Criteria Chapter 6 (Type 1 or 2) S System Architectures Chapters 7,8 (Type 1 or 2) T Advanced topics in systems, networks, Follow-on (Type 1 or 2); databases, architecture, system and Pursue bibliography software engineering, etc. U Advanced topics in survivability, Follow-on (Type 1 or 2); security, encryption, reliability, Pursue bibliography fault tolerance, error-correcting codes, etc. V Use of formal methods for critical Follow-on (Type 1 or 2); aspects of survivability Pursue bibliography W Management of development, quality Follow-on (Type 1 or 2), control, risk assessment, human Pursue bibliography factors, robust open-source, etc. X Prototype development projects, ideally Follow-on (Type 1 or 2), with collaborating teams, especially integrated with B sequence robustification of open-source software Table H: Survivability Curriculum Components
It is essential that the essence of this report be moved into the educational and institutional mainstream so that the valuable experiences of the past can be merged effectively with recent advances in computer and network technology, and thus encourage the development of truly survivable systems and networks in the future, and stimulate greatly increased awareness of the issues.
The following plan for courses that might contribute to an educational program is specifically oriented toward a systems perspective of survivability. Two types of course programs are identified, one on a small scale, the second on a much broader scale. However, the two types are compatible, and the differences are not intrinsic. Relevant curriculum topics are identified in Table H for each type.
The level of detail and the nature of the material selected should of course be carefully adapted to the academic level and experience of the students (e.g., college undergraduates, university graduate students, industrial employees, reentry individuals being retrained for new careers), and the background, training, and experience of the teaching staff. Many advantages can result from integrating requirements for survivability and its subtended attributes such as reliability, security, and performance, early in a <student's life. However, many of the subtleties of the system development process (e.g., team communication failures and the pervasiveness of system vulnerabilities) and many of the idiosyncrasies of procurement, configuration, and operation do not become meaningful to students until they have gained sufficient experience.
We make a distinction in the table between familiarity with programming languages and operating systems on one hand, and a deeper understanding of the principles thereof on the other hand. It is not adequate that students have merely been exposed to many different systems and languages. It is vital that they understand the fundamentals of those systems and what is really necessary in the future. Thus, the prerequisites or integrated units shown in the table for "A" through "E" are in the long run not necessarily the standard courses that exist today in their respective areas, but rather courses or units of courses that stress a grasp of the appropriate fundamentals. Nevertheless, exposure to some modern programming languages is highly desirable.
Ideally, an academic program incorporating survivability should have elements of survivability and its subtended requirements distributed throughout a considerable portion of the basic curriculum. In such an ideal world, those requirements would be addressed in the existing courses designated by "A" through "E" and "T" through "X" in Table H.
In contrast, survivability is almost never addressed today, and security and reliability are typically specialty subjects, and then only in a few universities. Similarly, software engineering may be taught as a collection of tools, rather than as a coherent set of principles. As a result, from a practical viewpoint, it would be very difficult to achieve a fully integrated approach as an incremental modification to existing course structures. On the other hand, it would be relatively easy to initially introduce a single new course addressing the items denoted by "S" in the table, and then evolve toward the desired goal of a coherent integrated curriculum.
Thus, our basic recommendation is to start small with the single course focusing on the "S" items most specifically related to survivability, and then over time to encourage faculty members to allow the concepts of survivability to osmose, pervasively working themselves into the broader academic program -- with particular emphasis on the design of operating systems and networking, and the use of programming languages and software engineering techniques to achieve greater survivability. In the process, the material in each course offering may change somewhat, including the material earmarked for the single type-1 course on survivability -- some of which may tend to be distributed among certain prerequisite courses.
One of the most fruitful areas for student projects involves the robustification of open-source software. The variety of approaches is enormous, the challenges are unlimited, and the opportunities for successful penetration into the real world are very exciting. The best results will find instant use on the Web. Collaborations with others can lead to continual improvements.
At present, no obvious textbooks can contribute directly to the intended breadth of the outlined survivability curriculum (other than perhaps this report, which in the first phase of the project has been primarily concerned with the fundamentals rather than the details -- which are yet to follow in the second phase). However, there are various books that can be extremely useful in filling in some of the gaps -- for example, addressing security (e.g., [300]), Java security and secure mobile code (e.g., [200] or, when available, [201]), and software engineering (e.g., [301]). Surprisingly, there does not seem to be an appropriately scoped modern book on fault tolerance, although there are some significant journal articles, such as [80] on distributed fault tolerance, and an early book on principles [18] that although out of print is still useful. Far-sighted good principles tend to remain good principles forever, despite changes in technology. However, the understanding and appreciation of those principles is highly dependent on their being illustrated by concrete examples. Furthermore, technological changes often tend to make optimization advice obsolete.
Many important articles should be mandatory reading for any students seeking a deeper understanding, quite a few of which are cited explicitly in this report. (See the Noteworthy References cited in Appendix D.) However, it is clear that someone needs to write an up-to-date textbook that could be used for the core portion of the proposed survivability curriculum. Perhaps this report will serve as the basis for such a book. On the other hand, books are often obsolete before they are published -- which is why this report has focused primarily on principles and their underlying motivation, as well as why it is important to study the literature.
Unfortunately, the prevailing mentality among many younger researchers and developers is fairly troglodytic when it comes to earlier works: "If it isn't on the Web today, it never existed in the past." Many extremely important works in the literature tend to be forgotten. (One effort to resuscitate some historically significant efforts is the History of Computer Security Project, which has created CD-ROMs of seminal papers. See http://seclab.cs.ucdavis.edu/projects/history for further information.)
As an outgrowth of the first-phase effort in our ARL project, with the
shepherding of Paul Walczak and George Syrmos at the University of Maryland,
a one-semester course of Type 1 noted above was taught by Neumann at the
University of Maryland in the fall semester of 1999. The course notes are
available in a copyleft
form on-line
(http://www.csl.sri.com/neumann/umd.html), freely available for use
elsewhere. The basic outline for the course is as follows:
1. Introduction and overview
2. Survivability-related risks
3. Risks continued, and Threats
4. Survivability requirements
5. Deficiencies in existing systems
6. Overcoming these deficiencies 1
7. Overcoming these deficiencies 2
8. Architectures for survivability 1
9. Architectures for survivability 2
10. Reliability in perspective
11. Security in perspective
12. Architectures for survivability 3
13. Implementing for survivability
14. Conclusions
In part inspired by the Maryland course and by the efforts of Paul Walczak in promoting the phase-one report, related courses were taught by Tony Barnes at the University of Pennsylvania, and by Doug Birdwell and Dave Icove at the University of Tennessee Knoxville, in the fall of 1999. Subsequently, a seminar on this subject was taught by Blaine Burnham at Georgia Tech, in the winter of 2000.
I must add that the Maryland course notes are to some extent my own personal view of what is important to teach, with considerable emphasis on basics, principles, and experience. Reflecting on my view that this material does not lend itself to a cookbook course, I have intentionally left gaps in the slide versions of some of the lectures (such as security and fault tolerance specifics), as an incentive for any lecturer using these materials to apply his or her own knowledge, and as an incentive for the student to dig into the literature. My own personal experience clearly infused my Maryland lectures. For example, I included some further material on David Huffman's beautiful work on graphical error-correcting codes for larger Hamming distances that is not included in the on-line slides. I would not expect someone else to teach such relatively unknown material, although I had a fascination with it because of its visual simplicity and my personal association with Huffman. Also, Virgil Gligor sat in with me for the 11th class period, Security in Perspective, adding his own very significant personal experience as well. That discussion is captured only briefly in summary. In general, the discussion periods during class time were very productive, because they addressed the specific concerns of the students - which are not easily captured in slides! Overall, I cannot stress often enough how far away the survivability problems are from having cookbook solutions.
Some universities and other institutions are offering or contemplating courses taught on-line via the Internet, including a few with degree programs. There are many potential benefits, as the multimedia technology improves with respect to audio, video, and sophisticated graphics: teachers can reuse collaboratively prepared course materials; students can schedule their remote studies at their own convenience, and employees can participate in selected subunits for refreshers; society can benefit from an overall increase in literacy -- and perhaps even computer literacy. On-line education inherits many of the advantages and disadvantages of textbooks and conventional teaching, but also introduces some challenges of its own:
The last of these challenges can be partially countered by including some live lectures or videoteleconferenced lectures, and requiring instructors and teaching assistants to be accessible on a regular basis, at least asynchronously via e-mail. Multicast course communications and judicious use of Web sites may be appropriate for dealing with an entire class. However, the reliability and security weaknesses in the information infrastructures suggest that students will find lots of excuses such as the "Internet ate my e-mail" variant on the old "My dog ate my homework" routine. Interstudent contacts can be aided by chat rooms, with instructors trying to keep the discussions on target. Also, students can be required to work in pairs or teams on projects whose success is more or less self-evident.
E-education may be better for older or more disciplined students, and for students who do not expect to be entertained. It is useful for stressing fundamentals as well as helping students gain real skills. But only certain types of courses are suitable for on-line offerings -- unfortunately, particularly those courses that emphasize memorization and regurgitation, or that can be easily graded mechanically by evaluation software. Such courses are also highly susceptible to cheating, which can be expected to occur rampantly whenever grades are the primary goal, used as a primary determinant for jobs and promotions. Cheating tends to penalize only the honest students. It also seriously complicates the challenge of meaningful professional certification based primarily on academic records.
Society may find that distance learning loses many of the deeper advantages of traditional universities -- where smaller classrooms are generally more effective, and where considerable learning typically takes place outside of classrooms. But e-education may also force radical transformations on conventional classrooms. If we are to make the most out of the challenges, the advice of Brynjolfsson and Hitt [65] suggests that new approaches to education will be required, with a "painful and time consuming period of reengineering, restructuring and organization redesign..."
There is still a lack of experience with, and lack of critical evaluation of, the benefits and risks of such techniques. For example, does electronic education scale well to large numbers of students in other than rote-learning settings? Can a strong support staff including in-person teaching assistants compensate for many of the potential risks? On the whole, there are some significant potential benefits, for certain types of courses. We hope that some of the universities and other institutions already pursuing remote electronic education will evaluate their progress on the basis of actual student experiences (rather than just the perceived benefits to the instructors), and share the results openly. Until then, we vastly prefer in-person teaching coupled with students who are self-motivated -- although there have clearly been some strongly positive experiences with videoteleconferencing.
If electronic materials are to be used in a survivability syllabus, we recommend starting modestly and then extending the offerings in a careful evolutionary manner.
The combination of architectural solutions, configuration controls, evaluation tools, and certification of static systems is by itself still inadequate. Ultimately, the demands for meaningfully survivable systems and networks require that considerable emphasis be placed on education and training of people at many different levels -- including high-level definers of high-level requirements, those who refine those requirements into detailed specifications, system designers, software implementers, hardware developers, system administrators, and especially users. The concept of keeping systems simple cannot be successful whenever the requirements are inherently complex (as they usually are). (Once again we recall the quotes from Albert Einstein given in Chapter 1.) Training large numbers of people to be able to cope with enormous complexity is also not likely to be successful. Although the mobile-code paradigm offers some hopes that education and training can be simplified, many vulnerabilities in the underlying infrastructure require human involvement, especially intervention in emergency situations. In short, our dictum throughout this report that "there are no easy answers" also applies to the challenges of education and training. There is no satisfactory substitute for people who are intelligent and experientially trained. But there is also no satisfactory substitute for people-tolerant systems that can be survivable despite human foibles. The design of systems and networks with stringent survivability requirements must always anticipate the entire spectrum of improper human behavior and other threats. We need intolerance-tolerant systems that can still survive when primary techniques for fault tolerance and compromise resistance fail, irrespective of unexpected human and system behavior. But above all we need people with both depth of experience and depth of understanding who can ensure that the established principles are adhered to throughout system development and maintained throughout system operation, maintenance, and use.
We conclude this appendix with yet another succinct quote from Albert Einstein, who serendipitously summarized the primary aim of our intended efforts to bring survivability concepts into mainstream curricula:
The development of general ability for independent thinking and judgment should always be placed foremost, not the acquisition of special knowledge. If a person masters the fundamentals of his subject and has learned to think and work independently, he will surely find his way and besides will better be able to adapt himself to progress and changes than the person whose training principally consists in the acquiring of detailed knowledge.
Albert Einstein, Out of My Later Years, The Philosophical Library, Inc., New York, NY, 1950, p. 36.
The wisdom of Einstein (embodied in quotations throughout this report) and Schopenhauer (in Section 9.3) emphasizes what should be the deeper purpose of any education relating to such a comprehensive subject as survivable systems and networks. Concerning Schopenhauer's view that experience must motivate the employment of general principles, we must also keep in mind that folks who start out with only experience and no principles also tend to go astray. Our own holistic view on the subject can be summarized as follows:
Perhaps this report in combination with other materials noted on the following page -- for example, [250] -- can provide a useful starting place.
Following is an enumeration of papers written at least in part under the
present ARL contract by Jon Millen. The first two represent fundamental
research on understanding some of the formalisms underlying survivability.
The remaining three papers are important contributions to modeling of
public-key infrastructures and digital certificates.
Local Reconfiguration Policies [214]
Survivable systems are modeled abstractly as collections of services supported by any of a set of configurations of components. Reconfiguration to restore services as a result of component failure is viewed as a kind of "flow" analogous to information flow. The paper applies Meadows's theorem [203] on dataset aggregates to characterize the maximum safe flow policy. For reconfiguration, safety means that services are preserved and that reconfiguration rules may be stated and applied locally, with respect to just the failed components.
A system is viewed as a collection of components configured to provide a set of user services. Electronic mail, for example, in a local-area network, requires a workstation, the cable and associated interface devices, a gateway to the Internet service, and so on. Components are not simply hardware devices, but functional combinations of hardware and software.
To study fault tolerance and reconfiguration, attention is focused on the fact that different sets of components can support the same service. Then, if some components fail, they can be replaced by others in a different configuration.
A service is characterized by the set of alternative configurations that can support it. A service configuration assigns components to support a service. A service configuration is not fully defined by the set of components it employs - two different configurations can use the same set of components. (An example is the use of "I" and "V" to support Roman numerals "IV" or "VI".)
At any given time, a system is in some state where a set of services is being supported simultaneously by the set of currently available components. Different subsets of these components are configured to support the various services in a way that respects the ability or inability of a component to be shared by more than one service.
Services are given a survivability ordering: one service is no more
survivable than another if every service set that supports the first also
supports the second.
Survivability Measure [216]
An as yet unpublished paper updating the earlier paper "Local
Reconfiguration Policies" [214] (itself
updating [215]) is ftp-able in PostScript form:
http://www.csl.sri.com/~millen/papers/measure.ps.
It includes new work at the end of the ARL project.
Efficient Fault-Tolerant Certificate Revocation [211]
This paper considers scalable certificate revocation in a public-key
infrastructure. It introduces depender graphs, a new class of graphs that
support efficient and fault-tolerant revocation. Nodes of a depender graph
are participants that agree to forward revocation information to other
participants. The depender graphs are k-redundant, so that revocations are
provably guaranteed to be received by all nonfailed participants even if up
to k-1 participants have failed. A protocol is given for constructing
k-redundant depender graphs, with two desirable properties. First, it is
load balanced, in that no participant need have too many dependers. Second,
it is localized, in that it avoids the need for any participant to maintain
the global state of the depender graph. The paper also gives a localized
protocol for restructuring the graph in the event of permanent failures.
Certificate Revocation the Responsible Way [217]
Public-key certificates are managed by a combination of the informal web of
trust and the use of servers maintained by organizations. Prompt and
reliable distribution of revocation notices is an essential ingredient for
security in a public-key infrastructure. Current schemes based on
certificate revocation lists on key servers are inadequate. An approach
based on distributing revocation notices to "dependers" on each certificate,
with cascading forwarding, is suggested. Research is necessary to
investigate architectural issues, particularly reliability and response time
analysis.
Reasoning about Trust and Insurance in a Public Key Infrastructure [218]
In the real world, insurance is used to mitigate financial risk to
individuals in many settings. Similarly, it has been suggested that
insurance can be used in distributed systems, and in particular, in
authentication procedures, to mitigate individuals' risks there. This
paper further explores the use of insurance for public-key certificates and
other kinds of statements. It also describes an application using threshold
cryptography in which insured keys would also have an auditor involved in
any transaction using the key, allowing the insurer better control over its
liability. It provides a formal yet simple insurance logic that can be used
to deduce the amount of insurance associated with statements based on the
insurance associated with related statements. Using the logic, it shows how
trust relationships and insurance can work together to provide confidence.
The more you know, the less you understand.
Lao Tze, Tao Te Ching
The material in this appendix is included primarily as an illustration of the difficulties in establishing architectural standards for systems and networks.
Several efforts have been made to provide some standardization for systems, the first three driven by the organizations under the U.S. Department of Defense, the fourth resulting from a nongovernmental task group that is explicitly targeted at advising the DoD.
We focus initially on the Army Joint Technical Architecture (JTA), Version 5.0 [90] and the extent to which it is relevant to the development and configuration of systems and networks with stringent survivability requirements. Irrespective of its possible benefits in constraining systems, we consider the JTA to be seriously deficient, and discuss the reasons therefor here.22
The three main goals of the Army Joint Technical Architecture (JTA) are very worthy: (1) provide a foundation for seamless interoperability among a very wide range of systems; (2) provide guidelines and standards for system development and acquisition that can dramatically reduce cost, development time, and fielding time; and (3) influence the direction of commercial technology development and R&D investment to make it more directly applicable. The intent of our present effort as described in this report is completely in line with those three goals.
To engage in a meaningful evaluation of the JTA, we must refer to the specific definitions of the three types of "architecture" defined therein.
The ellipses in these quoted definitions denote our elimination of references to the "war-fighter" -- because the scope of the JTA is explicitly intended to apply "to all systems that produce, use, or exchange information electronically" (JTA5.0, Section 1.1.3), including systems of other Armed Services. In the spirit of trying to use commercial systems wherever possible, it is vital that those systems be adequate for defense purposes rather than requiring extensively customized special-purpose systems.
The concept of the technical architecture must be understood within the overall problem of developing, configuring, and operating compliant systems - a process that is by no means a cookbook type of activity. By itself, the JTA is merely a set of guidelines, with no assurance of completeness or adequacy. Many of the requisite standards are not even established or sufficiently well defined, particularly with respect to survivability, security, reliability, and fault tolerance. Furthermore, highly survivable systems cannot be merely composed out of existing components, as noted in Chapter 4; the existing computer-communication infrastructures are still fundamentally flawed with respect to their ability to address many of the essential requirements. Consequently, our report is considered to be an essential additional set of guidelines, techniques, and principles for the development and procurement of highly survivable systems. We believe that our approach is generally consistent with the intent of all three of the technical, operational, and systems architectures.
The following recommendations are taken almost verbatim from an earlier assessment [259] of various ATA Version 4 drafts, written by Peter Neumann and Peter Boucher of SRI's Computer Science Lab. Those recommendations still seem timely, and in many ways anticipate our present study. We hope that our analysis may become obsolete as a result of subsequent improvements to the JTA that might occur during our project. Further changes to the JTA are increasingly essential, despite the fact that there have been almost no improvements in the JTA (apart from its renaming) in the past two years.
Ultimately, any system development and its operation depend on (among other things) (1) the availability of an accurate, flexible, realistic, and essentially complete set of functional requirements, (2) the existence of a conceptual architecture that can demonstrably satisfy those requirements, (3) a development process that can tolerate changes to the requirements and architecture during development, (4) competent personnel on the Government side, and (5) development personnel who provide a mixture of abilities including pervasive understanding of the requirements, appropriate technical skills, diligence, conscientiousness, responsibility, and a good practical sense regarding the development process. Without those constituent elements, the notions of a technical architecture, a systems architecture, and an operational architecture are of limited merit.
One of the biggest problems in the past has been that the initial requirements were improperly and incompletely stated and that the effects of subsequent changes could not be properly managed. This problem must be adequately addressed in the very near future.
The JTA Version 5.0 definition of a systems architecture suggests that a systems architecture is a physical implementation. That is in general a very unsound practice. A systems architecture should never exist only as a physical implementation, and is most desirably preceded by a conceptual logical architecture. More specifically, a physical implementation represents a system build, not an architecture. That definition violates basic principles of generality, abstraction, and reusability, and puts the cart before the horse. What is needed is a true systems architecture, namely, a logical realization of the functional requirements that can be readily converted into a physical implementation, but that does not overly constrain the physical implementation. There is always a serious danger of trying to use software solutions where hardware is essential, or of using inappropriate hardware where simple software approaches would suffice. A logical architecture must not be locked into irrevocable decisions that a few years later become totally obsolete.
Open architectures are essential. We strongly recommend recognition of the need for logical architectures in which there is considerable emphasis on servers (e.g., file servers, network servers, and authentication servers) and in which trustworthiness can be focused where it is most needed rather than distributed broadly. (See [267] and [310] for examples of how this can be done. Also, see [249] for a discussion of what trustworthiness can be accomplished if the cryptography is implemented in software instead of hardware, and some of the pitfalls of trying to rely on inadequately trustworthy infrastructure.)
Not sufficiently evident in the suite of three types of "architectures" is the notion of a generic, system-implementation-independent, reusable, abstract, architectural structure that could be implemented on different platforms to satisfy possibly related but different requirements, without prematurely constraining design decisions. Although in some sense an intent of the JTA approach, it is not sufficiently well motivated within the framework of the three JTA "architectures".
Chapter 6 of the JTA Version 5.0 is largely the same chapter that was rather belatedly incorporated into the ATA Version 4 to address information security, and is relatively unchanged despite the passage of two years -- although references have been added to the more recent DoD Goal Security Architecture (DGSA) intended for use with future systems. (See Section C.2 for discussion of the DGSA.) Unfortunately, the JTA has not been upgraded to adequately address its earlier deficiencies, and almost completely ignores survivability issues and survivability-related requirements other than security. This seems seriously shortsighted.
The following comments are essentially the same as those registered in January 1996 with respect to the drafts of ATA Version 4. It appears that only a few of our earlier comments were actually addressed, and thus the relevant comments from [259] are repeated here -- updated to encompass survivability issues.
Much greater guidance on how to interpret these standards and protocols needs to be included. Such guidance is absolutely essential to making the JTA approach practical.
It is still not clear how survivability policy, threats, vulnerabilities, and acceptable risks are intended to fit into the three "architectures". Presumably they are beyond the scope of the JTA, and must be addressed in the operational and systems architectures. But it seems to be impossible for the JTA to fulfill its intended purpose unless those concepts are explicitly accounted for. The process of establishing and accommodating the policy, threats, vulnerabilities, and acceptable risks must somehow be made explicit.
Some additional pointers to relevant standards and guidelines are nevertheless needed here. For example, a reference to NCSC-TG-007 ("A Guide to Understanding Design Documentation in Trusted Systems," Version-1, 2 October 1988, or any successor) might be useful for policy. CSC-STD-003-85 ("Guidance for Applying the Trusted Computer System Evaluation Criteria in Specific Environments" -- the Yellow Book) provides useful guidance for applying the NCSC security criteria, as does AR 380-19, Appendix B. Procedural, personnel, and physical security are also considered in AR 380-19. However, AR 380-19 is a bare-bones minimum, and itself is too hidebound by the TCSEC. For example, the password policy is somewhere out of the dark ages, and reflects none of the risks of passwords passing over an unencrypted network or otherwise vulnerable to capture, irrespective of how they are created. Relevant COMSEC policy standards would also be relevant here. Risk standards are mentioned only in passing, but should be referenced explicitly.
In JTA5.0 Section 6.2.1.1, the Orange Book (5200.28-STD) is mandated. (It is not even the best thing available, but at least some of its serious flaws and shortcomings should be recognized.) It would seem to be appropriate to mention the Yellow Book (CSC-STD-003-85, noted above) and at least acknowledge its limitations as well. Unfortunately, this is an example of why the mere mention of such references is inadequate -- we are not dealing with a cookbook process. Also, what about NCSC-TG-009 (Computer Security Subsystem Interpretation)? What about the Common Criteria as an emerging standard, which when instantiated with at least Orange-Book-equivalent requirements represents a significant improvement [although it still leaves much room for incompletely specified criteria]?
In JTA5.0 Section 6.2.2.1, the Fortezza material should be revisited.
In JTA5.0 Section 6.3.1.5, given the controversy and confusion relating to the Trusted Network Interpretation, it is not clear what is mandated. In addition, the TNI Interpretation document (NCSC-TG-011) should be mentioned.
Although it has been improved a little since the Version 4.x drafts, Table 6-1 (Protocols and Security Standards) could still become a much more useful table. The left-hand column still amorphously lumps together application, presentation, and session layers, transport and network layers, and in a second grouping datalink and physical layers. The middle column lists a few rather generic protocols. The right-hand column lists rather haphazardly a collection of security-related standards and protocols, with no relation to the middle column, whether the standards and protocols are actually adequate for any intended purposes (and if so, which), and no indication of whether any meaningfully secure implementations actually exist. (For many of these, the existing protocols and their implementations are seriously flawed.)
It would be useful to have a separate table (updated regularly) providing some guidance as to the state of the art, and enumerating current or anticipated implementations that are relevant. This table does not seem to fall naturally into any of the three "architectures", too specific for the JTA, too general for the systems architecture, and not appropriate for the operational architecture. The need for it suggests a new class of "architecture" documents, perhaps somewhat akin to the "interpretation" documents within the TCSEC rainbow series, such as the TCSEC [233], TNI [231], and TDI [232] and the corresponding interpretation documents for the TCSEC [234] and TNI [230]. Such an interpretation document could also include guidance on how to go from requirements ("operational architecture") to a generic architecture to the systems architecture, compliant with the JTA, and might also include some guidelines on system and software engineering. A guidance document would be extremely valuable, whether it is a part of the JTA document or otherwise.
JTA5.0 Section 6.4 is still very weak in comparison with the rest of the document. The fact that no standards are yet mandated is not encouraging for those relying solely on the JTA for their understanding of how to proceed.
JTA5.0 Section 6.5 is also weak. For example, much greater guidance is necessary relating to the security, complexity, and usefulness of user interfaces. In general, sophisticated user interfaces are very complex, difficult to use, and full of security flaws. This entire section has not been upgraded in the past two years, despite significant changes. The emerging standards for personal authentication in Section 6.5.2.2 are unrealistic. Zero-knowledge schemes are the tip of a very large iceberg for personal authentication, and everything else relating to cryptographically based one-time token authentication schemes, biometrics, and other approaches is lost in the shuffle by the mentioning only zero knowledge. Incidentally, this is an area in which the implicit inclusion of the basic TCSEC [233] (DoD 5200.28-STD) as a mandatory standard is misleading, because that document gives the distinct impression that fixed reusable passwords are perfectly adequate! Fixed passwords are in general a disaster waiting to happen, especially in highly distributed environments with components of unknown trustworthiness.
To give some examples of what is needed to bridge the gaps among the technical architectures of JTA Version 5.0, operational architectures, and systems architectures, several steps need to be taken.
In this section and in Chapter 6 on criteria, we paint a rather negative picture of the difficulties that have arisen repeatedly in procuring, developing, operating, using, and maintaining a wide variety of possibly unrelated systems and their networked interconnections. (See [250] for an elaboration and analysis of some of the risks involved.) On the other hand, the Technical Architecture document does represent a possibly useful step toward that goal if supplemented with other approaches. It must not be seen as a magic carpet on which we can fly into the future. We believe that the JTA and indeed the concept of the three Army "architectures" could be much more effective if the contents of our report are taken seriously.
The DoD Goal Security Architecture (DGSA), Volume 6 of the Technical Architecture Framework for Information Management (TAFIM) is intended to represent abstract and generic system architectures. The DGSA and the DGSA Transition Plan for bringing the DGSA into reality are both considered to be living documents, and therefore the reader is encouraged to check the on-line sources for the latest version (http://www.itsi.disa.mil/). Unfortunately, the evolution of these documents has been relatively slow.
The DGSA recognizes, among other things, (1) the importance of different security policies, (2) the reality that users and resources may have different security attributes, (3) the essential nature of distributed processing and networking, and (4) the need for communications to take place over potentially untrustworthy networks. It may be a useful step forward, but the proof of the pudding is in the eating and its potential utility is not yet realized.
A recent examination of the DGSA is given by Feustel and Mayfield [105], who remark that "Perhaps the DGSA document can best be viewed as a conceptual framework for discussing a security policy and its implementation." However, the DGSA leaves completely open which security policies are to be invoked. See also Lowman and Mosier [185], investigating the use of DGSA as a possible methodology for system development -- and giving two illustrative systems so described.
According to the DGSA document, an abstract architecture grows out of the requirements; it defines principles and fundamental concepts, and functions that satisfy those requirements. A generic architecture adds specificity to the components and security mechanisms. A logical architecture applies a generic architecture to a set of hypothetical requirements. Finally, a specific architecture applies the logical architecture to real requirements, fleshes out the design to enable implementation, and addresses specific components, interfaces, standards, performance, and cost.
For discussion purposes, the overview of the TAFIM volumes gives this summary of the TAFIM Volume 6: The DGSA "addresses security requirements commonly found within DoD organizations' missions or derived as a result of examining mission threats. Further, the DGSA provides a general statement about a common collection of security services and mechanisms that an information system might offer through its generic components. The DGSA also specifies principles, concepts, functions, and services that target security capabilities to guide system architects in developing their specific architectures. The generic security architecture provides an initial allocation of security services and functions and begins to define the types of components and security mechanisms that are available to implement security services. In addition, examples are provided of how to use the DGSA in developing mission-level technical architectures."
Although security policy is left unspecified in the DGSA, the requirements are focused on security and do not address other important aspects of survivability. In principle, that should not be an obstacle if the DGSA is sufficiently general to encompass survivability requirements as well. The extent to which this will be possible remains to be seen. In any case, in Chapter 7 we address architectural structures that could enhance the realization of the generalized survivability requirements outlined in Chapter 3.
The Joint Airborne SIGINT Architecture (JASA) Standards Handbook [121] (JSH) includes Chapter 7 (Security Services) and Annex 10 (Information Security and Information Systems Security Engineering). The handbook's Chapter 7 and Annex 10 appear to carry on the cookbook characteristics of the JTA and DGSA; they attempt to elaborate on the JTA and the Unified Cryptologic Architecture (UCA), which summarizes the primary cryptographic standards. Although such an enumeration of standards is certainly necessary, it leaves much unspecified and does not address the issue of compatibility; in particular, it leaves as an exercise to the reader how to achieve compatibility among incompatible approaches. It also exhibits a remarkable fascination with a secure single sign-on (SSSO) despite the reality that many of the components along the way typically cannot be trusted. This seems to be a monstrous oversimplification, and is dangerous because it is likely to encourage simplistic solutions that are not adequately secure. The handbook does recognize the need for SSSO approaches that can overcome the difficulties arising from multiple authentications (e.g., having to remember different account IDs and passwords), but the risks of trusting untrustworthy components and the serious risks of fixed passwords themselves are not adequately considered. (See Section 7.3.3.4.2 of the 30 June 1998 draft of the JASA Standards Handbook, Version 3.0.)
A very compelling statement is included in the Executive Summary of the OSTF: "In fact, the Task Force argues that major DoD priorities cannot be achieved without a massive infusion of Open System attributes through an organized Open Systems Process. Some sort of Open Systems Process must become the DoD mindset and core competency."
We make a distinction here between the open-system concept (which implies primarily that heterogeneously different systems can in some sense interoperate) and the open-box concept discussed in Section 5.10 (which additionally implies that the source code and interfaces are publicly available in some meaningful sense). Many of the arguments for the open-system approach recommended by the OSTF report are also relevant as motivation for pursuing the intrinsically open-box approach recommended in this report. However, the open-box approach is in our opinion much more compelling and much more far-reaching. In any event, we strongly urge the DoD to encourage both efforts.
Because this report addresses some of the most fundamental limitations of commercially available systems and what must be done to overcome those limitations, research is of critical importance to survivability -- both the incorporation of ongoing research and the conduct of new research that can help to fill in the gaps. As a consequence, considerable emphasis is placed on research references in the following bibliography. Although new additions to the literature are continually emerging, we have attempted to focus on the primary references, and particularly those that might illuminate a highly principled approach to survivability.
We cite here a few references that have been particularly influential in this project, and that we consider to be of historical significance in understanding the importance of architectural structure and its implications. Although the following subset of references is largely concerned with security, it also provides many valuable insights with respect to achieving survivability:
To illustrate the frequency and diversity of announced vulnerabilities, following is a list of the CERT Advisories in the past year, with initial date of release. (Please check the CERT Web site for the latest revisions subsequent to the date noted below.) There are also quarterly CERT Summaries.
* CERT Advisory CA-99.08, 16 Jul 1999:
cmsd
* CERT Advisory CA-99.09, 19 Jul 1999:
Array Services default configuration
* CERT Advisory CA-99.10, 30 Jul 1999:
Insecure Default Configuration on RaQ2 Servers
* CERT Advisory CA-99.11, 13 Sep 1999:
Four Vulnerabilities in the Common Desktop Environment
* CERT Advisory CA-99.12, 16 Sep 1999:
Buffer Overflow in amd
* CERT Advisory CA-99.13, 19 Oct 1999:
Multiple Vulnerabilities in WU-FTPD
* CERT Advisory CA-99-14, 10 Nov 1999:
Multiple Vulnerabilities in BIND
* CERT Advisory CA-99.15, 13 Dec 1999:
Buffer Overflows in SSH Daemon and RSAREF2 Library
* CERT Advisory CA-99.16, 14 Dec 1999:
Buffer Overflow in Sun Solstice AdminSuite Daemon sadmind
* CERT Advisory CA-99-17, 28 Dec 1999:
Denial-of-Service Tools
* CERT Advisory CA-2000-01, 3 Jan 2000:
Denial-of-Service Developments
* CERT Advisory CA-2000-02, 2 Feb 2000:
Malicious HTML Tags Embedded in Client Web Requests
* CERT Advisory CA-2000-03, 26 April 2000:
Continuing Compromises of DNS servers
* CERT Advisory CA-2000-04, 4 May 2000:
Love Letter Worm
* CERT Advisory CA-2000-05, 12 May 2000:
Netscape Navigator Improperly Validates SSL Sessions
* CERT Advisory CA-2000-06, 17 May 2000:
Multiple Buffer Overflows in Kerberos Authenticated Services
* CERT Advisory CA-2000-07, 24 May 2000:
Microsoft Office 2000: UA ActiveX Control Incorrectly Marked
"Safe for Scripting"
* CERT Advisory CA-2000-08, 26 May 2000:
Inconsistent Warning Messages in Netscape Navigator
* CERT Advisory CA-2000-09, 30 May 2000:
Flaw in PGP 5.0 Key Generation
* CERT Advisory CA-2000-10, 6 June 2000:
Inconsistent Warning Messages in Internet Explorer
* CERT Advisory CA-2000-11, 9 June 2000:
MIT Kerberos Vulnerable to Denial-of-Service Attacks
* CERT Advisory CA-2000-12, 19 June 2000:
HHCtrl ActiveX Control Allows Local Files to be Executed
PLWashington@jswg.org.